Wiktionary:Grease pit/2020/February
User page can't be created
editI'm trying to create my user page but it keeps being identified as harmful. Could you please assist?--Alexceltare2 (talk) 13:41, 3 February 2020 (UTC)
- Try using an interwiki link instead of an external link. — surjection ⟨?⟩ 13:43, 3 February 2020 (UTC)
Gadget-SpecialSearch redirects to HTTP
editAll four external search engines in MediaWiki:Gadget-SpecialSearch.js use HTTP URLs, rather than HTTPS. This can cause a browser warning: The information you have entered on this page will be sent over an insecure connection and could be read by a third party. Are you sure you want to send this information?
Three of them support HTTPS, though (Google, Bing and Yahoo do; Wikiwix does not), so it would be better to change their template to https://.... (Alternatively, since Wiktionary is HTTPS-only, a protocol-relative URL like //... would also work.) --Lucas Werkmeister (talk) 17:05, 5 February 2020 (UTC)
- @Lucas Werkmeister: That is an easy fix, so I've switched all but Wikiwix to HTTPS. Wikiwix timed out when I tried to access it over HTTPS. — Eru·tuon 20:11, 5 February 2020 (UTC)
Template:label
editDear colleagues,
In French Wiktionary, we are documenting and structuring our lexicons with new templates and modules, for categories structure and in pages, on definition lines (with data).
We are discussing the pro and con of building a template similar to your Template:label or to build three distinct templates with three lists: places, domains, contexts. As your are using label for a long time here, I though you may have some feedback or tips to share about this idea of having a big template for 1.000+ labels. Is it easy to learn for newcomers? Is it easy to use for contributors? Is it easy to parse for reusers? I hope it is not a conflictual topic and thank you in advance for your help with this matter ![]() Noé 10:30, 7 February 2020 (UTC)
Noé 10:30, 7 February 2020 (UTC)
Can anyone explain why Lua memory is ≈ 47.3 MB when I preview it, but maxed out at 50 MB after I click "Publish changes" (null edit)? — This unsigned comment was added by Chuck Entz (talk • contribs).
error when auto-generating pinyin entries
editCould someone please help me here? I keep getting the following error message when I try to auto-generate pinyin entries: "Lua error in Module:languages at line 453: Please enter a language code in the parameter "lang". The value "cmn-Latn-pinyin" is not valid." @Benwing2 @Erutuon ---> Tooironic (talk) 04:49, 11 February 2020 (UTC)
- @Tooironic It doesn't happen for me any more on 站赤. As User:Chuck Entz pointed out, you may need to do a null edit on a page to make the error go away. Benwing2 (talk) 05:37, 11 February 2020 (UTC)
- Thanks everyone, it's working now. ---> Tooironic (talk) 05:43, 11 February 2020 (UTC)
- For the record, I'll write out my own understanding of the problem. As noted in User talk:Justinrleung § error when auto-generating pinyin entries, this was the edit that caused the problem, changing
lang="cmn"tolang="cmn-Latn-pinyin".cmn-Latn-pinyinis an IETF language tag meant to represent Mandarin written in pinyin (though I think it should bezh-Latn-pinyinaccording to the language subtag registry:zh-Latnis listed as a prefix for thepinyinsubtag, butcmn-Latnisn't). I noticed the edit at the time and thought it might be okay. But the change was in a HTML tag that also had acceleration information, so the language code was picked up by the accelerated form creation script (WT:ACCEL). The script uses a module (Module:accel) to generate the new entries, and sends it the language code. But the module requires the language code to be an official Wiktionary code, whichcmn-Latn-pinyinis not, so there was a module error. - In theory the acceleration script or the module could parse the IETF language tag
cmn-Latn-pinyin(though it may be invalid) and pick out the Wiktionary language code at the beginning while ignoring the rest, though it's odd to use an IETF language tag here and almost nowhere else on Wiktionary. It is probably a good idea to use IETF language tags instead of or alongside Wiktionary language codes, because they are apparently the correct way to identify languages on the internet, but someone would have to figure out how to implement it in our module system (and hopefully avoid causing a lot more Lua memory errors). — Eru·tuon 07:05, 11 February 2020 (UTC)
Missing in Wales
edit@Benwing2: I noticed when revising Holyhead that Anglesey is missing from Category:en:Places in Wales. Whether it should be shown as Anglesey (which is more convenient) or Isle of Anglesey is another matter: see Local government in Wales#Principal areas of Wales and Isle of Anglesey County Council. Maybe use of Anglesey in entries could redirect to Isle of Anglesey. DonnanZ (talk) 12:59, 11 February 2020 (UTC)
- @Donnanz Anglesey was missing from Category:en:Places in Wales because it had a manually-specified place entry instead of using
{{place}}. I fixed that but also had to fix a module bug involving 'traditional county', which was wrongly failing to categorize this page under Category:en:Counties of Wales. I also added a category alias for county 'Anglesey' that maps it to 'Isle of Anglesey'; see Holyhead and its categories now. Benwing2 (talk) 03:39, 12 February 2020 (UTC)- @Benwing2: Ah, OK, thanks. I meant it's missing from the subcategories, but that should appear any day now? As is all too common, the local government history is a little complex, Anglesey was part of Gwynedd from 1974 to 1996 (so I added that to the entry). I will probably have to update more Wales entries. DonnanZ (talk) 11:12, 12 February 2020 (UTC)
Request: checktrans bot run
editA lot of translations to be checked aren't getting checked. In the cases where a human has added the translation to the entry, and the translation to be checked is the same translation, the checktrans can simply be removed (example diff, where Afrikaans eier is already in the first translation table). Would anyone be interested in running a bot to remove these? —Μετάknowledgediscuss/deeds 00:44, 12 February 2020 (UTC)
- @Metaknowledge Hi, missed your message from a few days ago. I'll look into running a bot to do this, it shouldn't be too difficult. Benwing2 (talk) 19:18, 15 February 2020 (UTC)
- @Benwing2: Thanks, here's a reminder. —Μετάknowledgediscuss/deeds 19:36, 23 February 2020 (UTC)
- @Metaknowledge Sorry, I'll see about implementing this today. Benwing2 (talk) 19:51, 23 February 2020 (UTC)
- @Metaknowledge I looked into this. One potential concern is that the translations to be checked are in a separate section that might correspond to multiple translation meanings, and not all of them may be present. For example, you removed Afrikaans eier as a translation to be checked based on its presence under the heading "egg of domestic fowl as food item", while it might well apply also to "body housing an embryo", "ovum" and/or "something shaped like an egg" (but isn't currently present in any of them). It could be argued that only a human editor should remove the checktrans, after checking all meanings. However, this is probably unrealistic. Benwing2 (talk) 20:41, 23 February 2020 (UTC)
- @Benwing2: A lack of a translation does not mean that the translation is wrong, whereas a checktrans is implying that there may be something wrong with the translation. As a result, this still wastes less human effort on translations to be checked, even if some senses lack translations. (And as you noted, checking every sense ranges from unrealistic to impossible.) —Μετάknowledgediscuss/deeds 21:07, 23 February 2020 (UTC)
- @Metaknowledge I looked into this. One potential concern is that the translations to be checked are in a separate section that might correspond to multiple translation meanings, and not all of them may be present. For example, you removed Afrikaans eier as a translation to be checked based on its presence under the heading "egg of domestic fowl as food item", while it might well apply also to "body housing an embryo", "ovum" and/or "something shaped like an egg" (but isn't currently present in any of them). It could be argued that only a human editor should remove the checktrans, after checking all meanings. However, this is probably unrealistic. Benwing2 (talk) 20:41, 23 February 2020 (UTC)
- @Metaknowledge Sorry, I'll see about implementing this today. Benwing2 (talk) 19:51, 23 February 2020 (UTC)
- @Benwing2: Thanks, here's a reminder. —Μετάknowledgediscuss/deeds 19:36, 23 February 2020 (UTC)
problem with Japanese categories
editPlease take a look at this edit. The みな entry has two etymology sections corresponding to two lexical items. [[Category:Japanese basic words|みな]] belongs to the first lexical item, so it should be put at the end of Etymology 1, but the bot moved it to the end of the whole Japanese section. As a result, the soft-redirect to みな1 failed to copy that category.
Possible solutions (in increasing difficulty):
- Allow Japanese categories to appear at the end of the individual lexical items, not just of the whole ==Japanese== section.
- Use homonym numbers in page titles (e.g. みな/ja/1, みな/ja/2), rather than lumping unrelated lexical items in a single page. "Spelling hubs" like みな can contain a single template to transcribe the subpages (with automatic alphabetization and <hr>) Write an entry creation wizard to automatically update the related structures (for example, when creating 御名(みな), put it in 御名/ja and create みな/ja/3 as a soft-redirect. Then when creating 御名(ぎょめい), move 御名/ja to 御名/ja/1, etc.)
- Go database-like.
@DTLHS --Dine2016 (talk) 04:26, 15 February 2020 (UTC)
- @Dine2016, DTLHS The only realistic solution is to allow Japanese categories to appear at the end of Etymology sections. This shouldn't be difficult, it just means that User:NadandoBot needs to have a special case to not move categories to the end of the language section if the language is Japanese (do any other languages need this special casing?). Benwing2 (talk) 19:21, 15 February 2020 (UTC)
- I will blacklist all Japanese entries from any automatic formatting. They have diverged way too much for the rules that are used for other entries to be of any use. DTLHS (talk) 01:56, 16 February 2020 (UTC)
- Thank you, though I think it's Wiktionary's entry layout that has diverged from the rules of other dictionaries. Lumping unrelated lexical items in a single entry makes cross references difficult, especially for languages like Japanese with a lot of spelling variants and homographs. --Dine2016 (talk) 03:04, 16 February 2020 (UTC)
- I will blacklist all Japanese entries from any automatic formatting. They have diverged way too much for the rules that are used for other entries to be of any use. DTLHS (talk) 01:56, 16 February 2020 (UTC)
Western Isles
edit@Benwing2: Use of carea/Western Isles doesn't generate a category, not even a red link. I'm not sure why. I used it for Stornoway and Benbecula. DonnanZ (talk) 15:29, 15 February 2020 (UTC)
- @Donnanz Fixed. I had this council area listed under "Na h-Eileanan Siar", which is the form used in Wikipedia. I've added "Western Isles" as a category alias for "Na h-Eileanan Siar", hope this is the correct thing to do. Benwing2 (talk) 19:16, 15 February 2020 (UTC)
- @Benwing2: Yeah, I guess so, apparently it's the official name in English too (since 1997), and the majority of the population speak Scottish Gaelic. I haven't got any up-to-date maps of the area, so I can't check those (only one from 1973 bought second-hand). Cheers. DonnanZ (talk) 19:51, 15 February 2020 (UTC)
Eastern Mari (chm)
editThe translation adder fails on Eastern Mari (chm), e.g. эҥыремыш (eŋyremyš, “spider”) on spider#Translations. It should be nested as follows:
* Mari:
*: Eastern Mari: {{t|mhr|эҥыремыш}}
The Western Mari (mrj) should also work (it does).--Anatoli T. (обсудить/вклад) 00:32, 18 February 2020 (UTC)
Weird formating
editSome weird shit happened at Alta California with WingerBot (talk • contribs)'s edit. Needs fixing urgently, as do, I imagine other pages --AcpoKrane (talk) 10:43, 21 February 2020 (UTC)
- Already fixed and Benwing has been notified on his talkpage. —Μετάknowledgediscuss/deeds 23:56, 21 February 2020 (UTC)
I before E
editYou get a lot of entries ending up in Category:English words following the I before E except after C rule for which it wasn't designed for - e.g. Anniesland. What can be done about it? DonnanZ (talk) 20:46, 21 February 2020 (UTC)
- My suggestion is to do nothing. It was a poorly thought-out category to start with. --AcpoKrane (talk) 19:01, 22 February 2020 (UTC)
- We have a number of categories in the pattern "[language name] terms spelled with [character]". This category would be analogous to "[language name] terms spelled without [character]"- utterly useless, and partly wrong:
- Strictly speaking, the rule only prohibits "ei" when not following "c". It doesn't prohibit "ie" anywhere, and it doesn't apply at all after "c". Our inclusion logic is based on a different rule: "I before E not
beforeafter C and E before I after C". - As for Anniesland, if Annie is included, then Anniesland should be also. Chuck Entz (talk) 20:41, 22 February 2020 (UTC)
- "I before E not before C and E before I after C", besides being hard to parse, is wrong. (If I'm misunderstanding it, see previous sentence.) Why not use "I before E except after C", which I know as the traditional form of the mnemonic? It makes no explicit mention of what happens before C, but those cases are a subset of the "not/except after C" cases, which default to "I before E", and including them here only muddles the issue.
Please{{ping}}me if replying.--Thnidu (talk) 18:08, 30 March 2020 (UTC)- @Thnidu. An absent-minded mistake on my part. Fixed. Chuck Entz (talk) 18:19, 30 March 2020 (UTC)
- @Chuck Entz Wow, that was quick! I suspect an unexpected benefit of social distance / staying in. --Thnidu (talk) 18:25, 30 March 2020 (UTC)
- @Thnidu. An absent-minded mistake on my part. Fixed. Chuck Entz (talk) 18:19, 30 March 2020 (UTC)
- "I before E not before C and E before I after C", besides being hard to parse, is wrong. (If I'm misunderstanding it, see previous sentence.) Why not use "I before E except after C", which I know as the traditional form of the mnemonic? It makes no explicit mention of what happens before C, but those cases are a subset of the "not/except after C" cases, which default to "I before E", and including them here only muddles the issue.
- Why don't we get rid of this category and those like it? It was added to the en-headword module by some random person who isn't really involved in this project, no idea why. Do we really need one of the most commonly called modules on the project to check, for instance, if a word ends in yre? - TheDaveRoss 20:44, 30 March 2020 (UTC)
- The only benefit I can think of is that it saves the trouble of generating it from the dump or MediaWiki API or a replica database. But I agree that generating it some other way is preferable. — Eru·tuon 21:30, 30 March 2020 (UTC)
Including most recent additions to a category.
editSome of the overcomplicated templates used on categories can show the newest (and oldest) additions found in the category, like Category:Requests for date/Shakespeare. How can this cool gadget be added manually to a category? --AcpoKrane (talk) 17:57, 22 February 2020 (UTC)
- Instead of telling me how to do it, I'm gonna change this post to a request. Can this feature be added to Category:Word of the day archive? --AcpoKrane (talk) 17:59, 22 February 2020 (UTC)
Very weird Lua memory behavior
edit@Erutuon, Rua I made this diff: [1] and it caused an OOM on Albania. Without the change, the memory usage is 49.37 MB out of 50 MB. I've tracked the issue down to the following:
if display_form then for _, mod in ipairs(place[4]) do if (mod == "pref" or mod == "Pref") and place[1] then ps = (mod == "Pref" and m_strutils.ucfirst(place[1]) or place[1]) .. " of " .. ps if needs_article then ps = "the " .. ps end end end end
If I remove this clause, the memory goes back down to 49.38 MB. If I change this to if display_form and nil then so the if-clause doesn't run, the error still occurs. You can remove individual lines and at a certain point it suddenly goes from > 50 MB to 49.37 or 49.38 MB. It's almost as if there's a threshold of code size where Lua suddenly uses significantly more memory to handle it. Benwing2 (talk) 18:58, 22 February 2020 (UTC)
- The strings created in the loop should take a little more memory in themselves, but I'd guess that the large jump is related to the randomness of garbage collection. Maybe the extra allocations in the invocations of
{{place}}in Albania caused garbage collection to behave differently, maybe to collect less memory at certain points in execution, so memory usage jumped by significantly more than the amount of memory used by the strings. I don't really understand how Lua garbage collection works, but I know it doesn't immediately free the memory for an object when the object isn't referenced in code, so memory usage, by whatever measurement Scribunto uses (which I haven't figured out), can't always be exactly predicted based on the total size of the objects in Lua code. — Eru·tuon 00:33, 23 February 2020 (UTC)- @Erutuon Thanks. The weird thing is that the memory jump happens even if the code above doesn't execute at all (if I change
if display_form thentoif display_form and nil then). Literally, the presence of unexecuted code makes the difference. So it's hard for me to chalk it up to the vagaries of GC. Benwing2 (talk) 05:55, 23 February 2020 (UTC)
- @Erutuon Thanks. The weird thing is that the memory jump happens even if the code above doesn't execute at all (if I change
Potential bot run to remove sc=Foo
editI am thinking of doing a bot run to remove sc=Foo params for most scripts. These are especially (but not exclusively) present in {{t}}, {{t+}} and the like. I'm aware this might not be safe for Chinese-character scripts (not sure about this), but it should be safe for most or all others. If there are concerns, I could start out with only certain scripts (e.g. Cyrillic), and check that the specified scripts of the lang code in question contain the script to be removed. Another possibility is to run script detection and make sure the autodetected script agrees with the script to be removed. Benwing2 (talk) 20:47, 23 February 2020 (UTC)
- @Benwing2: I think that it's safest to remove it when the autodetected script is the same, since autodetection might fail. But I could write a script to see just how frequent that is. It would happen for instance when a linked term consists of ASCII punctuation or whitespace. — Eru·tuon 01:43, 24 February 2020 (UTC)
- @Erutuon I wrote a script to do this check. Some of the most frequent offenders come from Korean entries in translation tables, where
Koreis autodetected butHaniis given explicitly (which isn't one of the listed scripts for Korean). Here's an example of how they look: - For me they look slightly different but I don't know which one is better.
- (Notifying TAKASUGI Shinji, Atitarev, HappyMidnight): Can one of you tell me which one is either better or intended? Thanks! Benwing2 (talk) 05:04, 25 March 2020 (UTC)
- @Benwing2: Use the default for Korean. The use of sc=Hani for Korean is silly, the Korean templates display Chinese characters as they should be displayed. IMO, it's safe to remove sc=Foo Chinese-character scripts - Chinese lects. If Chinese terms are completely written in Roman letters (undesired but possible, especially for dialects), then auto-detect should make it sc=Latin implicitly. --Anatoli T. (обсудить/вклад) 05:16, 25 March 2020 (UTC)
- @Erutuon I wrote a script to do this check. Some of the most frequent offenders come from Korean entries in translation tables, where
Chinese:
Korean:
How do they look? On my PC, Hans and Hant are correctly distinguished in Chinese and Hani is wrong in Korean, but not on my smartphone. — TAKASUGI Shinji (talk) 08:11, 26 March 2020 (UTC)
Template:fr-noun where a noun can take either gender
editberzingue can be either masculine or feminine (source: fr.wikt). Template:fr-noun does not seem to allow for this possibility. Equinox ◑ 19:51, 24 February 2020 (UTC)
- Using g2 seems to work. — surjection ⟨?⟩ 10:46, 25 February 2020 (UTC)
- Even further, mf is allowed as an alias of m|g2=f. — surjection ⟨?⟩ 10:47, 25 February 2020 (UTC)
Etymology templates in senses
editI see in the documentation that etymology templates {{inherited}}, {{borrowed}}, etc., are only supposed to be under an Etymology section, but there are a number used inline in senses. I was changing some of them to {{derived}} but I just noticed that it, too is only for Etymology sections. Is there a simple replacement, or would it be better to use use ordinary links for senses (especially in surnames) for "derived from...", etc.? Uranographer (talk) 09:45, 26 February 2020 (UTC)
- For surnames, Template:surname supports a from= parameter. In general (including for information like in Malthus, where a Middle English word is specified and not just bare derivation from Middle English), this info should be moved to the etymology section at the top. If there are multiple senses, then add notes about which sense has which etymology (or split by etymology, if the difference is substantial and not just "the surname is from x, and later came to be used as a given name / the given name is from the surname" like in Kelly). - -sche (discuss) 18:43, 26 February 2020 (UTC)
I just made a page for the french noun champ' and something weird is going on in the noun section where some square brackets are showing up after the word, I can't seem to see what in the code is causing this and I assume it has something to do mabe with how the word ends with an apostrophe. Does anyone know how to fix this? Thanks! 2WR1 (talk) 09:55, 28 February 2020 (UTC)
- On a similar note to the above, I've also noticed that on the page pin's, another french word with an apostrophe in it, in the noun section it's trying to separate it into two words, is there someway to tell the code that it should be taken as one unit? 2WR1 (talk) 09:59, 28 February 2020 (UTC)
- You need to explicitly specify
|head=. I've used curly apostrophes on these two words cuz I'm fond of curly apostrophes, but straight ones would work as well. —Mahāgaja · talk 12:50, 28 February 2020 (UTC)- Thanks so much! 2WR1 (talk) 13:38, 28 February 2020 (UTC)
- You need to explicitly specify
abbreviation of and not abbreviation of
editHey. Can someone make a list of all entries containing "abbreviation of" without {{abbreviation of}} or any redirects thereto? To put at Wiktionary:To do/Abbreviation of and not abbreviation of --AcpoKrane (talk) 13:30, 29 February 2020 (UTC)
Picture labels not displaying correctly
edit| Picture dictionary | ||
|---|---|---|
|

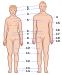
The adjacent image is included in the article at face. For me, the labels are in the wrong places; for example, "eyebrow" is too far to the left so that I can only see the letters "ebrow", and "nostril" is also too far to the left, quite a way from her actual nostril. I thought at first that everything was just shifted left, but this is not true of "mouth", which is, if anything, too far to the right (or could be in the intended place), and "eye" seems too low too. The documentation says "The coordinates [of the labels] are the number of pixels from the upper-left-hand corner of the visible size of the image" but unhelpfully does not explain which part of the text the coordinates locate. Is it the top left corner of the text? If so, the text is not for me displaying in the specified locations. I wonder whether this is some local setting-dependent glitch or something. It seems unlikely that the person who created the picture could have failed to notice these problems. I don't want to "correct" it and then make it wrong for everyone else. Perhaps others could take a look and check whether the labels display in the wrong positions for them too, and what might be done about it. Mihia (talk) 18:44, 29 February 2020 (UTC)
- FWIW I see the same problems ("ebrow", etc) as you, both when logged in and when logged out. - -sche (discuss) 21:21, 29 February 2020 (UTC)
- I removed the picture. Seemed the best thing to do. Meh --AcpoKrane (talk) 09:30, 1 March 2020 (UTC)
- I (logged in) see the same problems. PJTraill (talk) 19:14, 14 March 2020 (UTC)
"Lua error: not enough memory"
editThis edit to face has introduced dozens of red "Lua error: not enough memory" errors. I see no errors in the pre-edit version of the article, and dozens in the post-edit version. Also pinging the editor concerned, @Atitarev, not that I can say that he or she has necessarily done anything wrong. Mihia (talk) 23:46, 29 February 2020 (UTC)
- This page is right on the edge of running out of memory. I added it to the exclusion list at
{{redlink category}}, which cleared the error for now, but it needs to have some of the translations changed from{{t}}and{{t+}}to{{t-simple}}to get it out of the danger zone. Either that or move the translations to a subpage. There are a number of pages with large translation sections that have similar potential for problems. The precise amount of memory used varies unpredictably. I just clicked "Edit" and "Show preview" on the English section itself and got an "out of memory" error that I don't get if I do the same for the entire entry. The memory usage for the entire entry is displayed as 49.36 MB, however, and my experience is that unexplained variance of a MB or two is to be expected. Chuck Entz (talk) 00:28, 1 March 2020 (UTC)- OK, thanks. 49.36 MB seems a crazy amount of memory to need to process this page. The entire source of the page is only 44K. Whatever is it doing, I wonder? Mihia (talk) 03:03, 1 March 2020 (UTC)
- I have moved translations to face/translations. --Anatoli T. (обсудить/вклад) 03:10, 1 March 2020 (UTC)
- OK, thanks. 49.36 MB seems a crazy amount of memory to need to process this page. The entire source of the page is only 44K. Whatever is it doing, I wonder? Mihia (talk) 03:03, 1 March 2020 (UTC)