Wiktionary:Beer parlour/2009/May
| This is an archive page that has been kept for historical purposes. The conversations on this page are no longer live. |
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
May 2009
Bot for adding audio
Can someone review latest edits of my bot adding pronunciation files before I run it normally on more entries? --Derbeth talk 15:06, 1 May 2009 (UTC)
- I've had a look. The edits seems fine (I didn't listen to any of the files, just have to assume they are correct). I made a couple of changes: Absolute and here where an {{also}} was missing, but I'm sure that doesn't upset the bot. I'd say run it again. --Jackofclubs 12:32, 3 May 2009 (UTC)
- I didn't spot any problems. --EncycloPetey 14:02, 3 May 2009 (UTC)
- Actually, there might be a couple of things to review: homographs and US/UK files. I compiled a mini list of recent bot additions to homographs at User:Jackofclubs/nothing, which should be moved to a relevant section. I don't suggesting stopping the bot for it, just for a human editor to put them in the right place. I could do it when I get time, but my sound card isn't working. --Jackofclubs 15:08, 4 May 2009 (UTC)
Bot's work is over. Page User:DerbethBot/May 2009 provides statistics how many files were added plus a list of files that could not be added. They can be inserted manually. --Derbeth talk 22:37, 5 May 2009 (UTC)
Category names
There's a bit of a problem with the names of categories on this Wikt. For example Category:Meats, should I add [[fr:Category:Meats in English]] or [[fr:Category:Meats]] (translated into English here, clearly). The same for the reciprocal links, should [[fr:Category:Meats in English]] just link to Category:Meats? If possible, getting a bot to change the links to Category:en:Meats would solve this problem, or is it just too much effort for such a trivial problem? Mglovesfun 09:40, 2 May 2009 (UTC)
- We deliberately have not used :en: for topical categories because this is the English Wiktionary. The word "English" only appears in lexical categories (about the nature of the word), never the names of topical ones (which treat the meaning of the word). This is not a problem; it is a conscious choice we made. --EncycloPetey 14:04, 3 May 2009 (UTC)
- Or rather, it's a choice that was made which we consciously didn't unmake. DAVilla 18:58, 3 May 2009 (UTC)
Sanskrit
Can someone who knows Sanskrit check out the contributions of user:71.138.140.129, mostly reverted by user:67.116.243.171 (and then restored by me, because that reverting user didn't respond to DAVilla's query on his talk page and I took him/her to be a vandal)? Equinox ◑ 00:32, 4 May 2009 (UTC)
- As well, it could be that the first user didn't know what he was doing. Or that it's the same person, who is realizing his mistake. That's why I asked. DAVilla 01:11, 4 May 2009 (UTC)
Ramifications of assisted editing
Assisted editing avoids a lot of the need for specific knowledge, whether of wikitext or of our fairly rigid formatting. This is definitely the direction of future growth. What I'm thinking is that with this functionality expanded to other areas, it might be possible to restrict contributions from anonymous editors through the tools provided. Link an audio file at the click of a button. Adding a derived term would only be allowed if the term already existed in the target language. The javascript would automatically alphabetize and balance it, and we wouldn't have any of the additional crud that sometimes goes along with those. (New users tend to try to define the term there.) Clicking on a red link in translations would automatically fill in the language header and a starter definition for those logged in, and would query for more information on a form for those who are not. Basically, we want to make it easy for anons to make positive contributions, especially translators who don't often bother to log in on every project, but we have the right to expect any direct changes to the wikitext to be made by knowledgeable contributors who have at least taken the time to create a username, never mind the time to read through all of our guidelines.
It has always been the case here that the volume of edits require hasty decisions in patrolling, and the result is that a number of potential repeat contributors are turned away from a first bad experience, for being blocked in the creation of words like outgreen which may not appear in other dictionaries but are real nonetheless. The problem is that we get so many bogus entries that these positive contributions are misinterpreted. It would be extremely convenient to channel our energy at directing those who have taken the trouble of registering, while at the same time not requiring such a high barrier on minuscule edits that provide a long tail of content. Seeing the objections that have arisen from this first assisted test case, it is evident that these sorts of tools can only be applied where the formatting is very rigidly defined, so I wouldn't expect for instance Wikisaurus pages to be collectively protected in a very long time. I have believed for some time that our format differing from Wikipedia will require an independent solution in the long run, one that seamlessly links definitions with their synonyms and translations for instance. I have some hope now that this will actually come about because with experimentation outside of the wikimedia framework it can happen in steps and only be fully incorporated when maturated. 72.177.113.91 03:00, 4 May 2009 (UTC)
- "Adding a derived term would only be allowed if the term already existed in the target language." Do you mean translations? What's the point of having too many, if there isn't just one? I would allow to add the very first translation to a missing language to anyone. The regular members may not have the knowledge of that language or be bothered about it. Anatoli 03:06, 4 May 2009 (UTC)
- I don't mean translations, I mean derived terms. We could apply what we've done with translations to derived terms with a convenient input box. And likewise with other sections. Now edited above to be clearer.
- As to fleshing out translations, I agree. In contrast to Wikipedia, we do not protect against new page creation because we need those entries very badly. 72.177.113.91 03:18, 4 May 2009 (UTC)
Re-ordering ELE sections
"Re-ordering the descriptive paragraphs is just fine; if you stick to that there is no issue." -- RU, commenting on the previous VOTE which included this proposal
The proposal: Re-ordering the ELE sections Derived terms, Related terms, and Descendants to match the Order of Headings section.
Why don't we try this again. Since I now believe that merely re-ordering three sections is too trivial to require a full VOTE, maybe if I mention it at the BP, someone will be willing to be bold and simply do it. Or, maybe some kind soul will go through the rigamarole of a VOTE, then (a month later) make the minor change. In any case, hopefully this will provide further evidence of discussion, or at least the attempt to provoke such. JesseW 17:09, 4 May 2009 (UTC)
- Perhaps we need to aggregate proposed "minor" changes. We should exclude any that have any significant controversy or are substantive. As I understand it, this is roughly how it is done in most legislative bodies. If we do not limit ourselves to non-controversial items, we may not get any changes through. If we slip in substantive changes, they may not get the benefits of serious attention. DCDuring TALK 16:43, 11 May 2009 (UTC)
- Well, I've now tried making the edit again -- we'll see if someone jumps on it. JesseW 20:05, 12 May 2009 (UTC)
Recurring problem with Chinese vs. Mandarin
Why is Mandarin more correct?
Because we distinguish the Chinese languages, so "Chinese" is ambiguous. This is not a debate between whether Mandarin is a dialect or Chinese a language family. Linguistically the distinction between dialect and language is arbitrary. The point is that we do not group all Chinese words together, so our nomenclature should reflect the way these are grouped. That's why ==Mandarin== is the approved and de facto language header. The problem is that many of our Mandarin Chinese translations do not say "Mandarin" at all. DAVilla 17:25, 4 May 2009 (UTC)
- There's no problem in Mandarin being more correct, we just shouldn't use "zh" to reference it, "zh" is Chinese. Conrad.Irwin 22:59, 4 May 2009 (UTC)
- I need to change the template (zh) to "Chinese" to help me with the assisted translations. Asking you not to revert, please. ("cmn" still exists and can be used). In any case, I don't know how we can reconcile our differences. If the majority decides on Mandarin, renaming all * Chinese to * Mandarin translations may require some bot program, if I add extra translations, it won't make much difference. zh still stands for Chinese (中文 (Zhōngwén)), not for Mandarin. (普通話 / 普通话 (Pǔtōnghuà), and other words meaning standard Mandarin or northern Chinese dialects). Anatoli 01:52, 5 May 2009 (UTC)
- We don't use zh to reference it, we use cmn. The reason that
{{zh}}says Mandarin is that Wikimedia uses zh to refer to Mandarin. The Wiktionary at zh.wiktionary.org does not include other dialects of Chinese. Aside from that there is no purpose for zh at all. DAVilla 06:49, 5 May 2009 (UTC) - But don't take it from me. See Wiktionary:Beer parlour/2009/March#lang=zh. DAVilla 09:34, 5 May 2009 (UTC)
- Text below moved here from my talk page.
- "zh" should really not be "Mandarin" in the template. No one uses "Mandarin" as the term for translations in Wiktionary; everyone uses "Chinese". So it's quite inconvenient for us to change it to Mandarin. "cmn" gives you "Mandarin" anyway. (And this is not a problem; after all, Chinese means Mandarin, effectively. For Chinese people, there is only one standard Chinese language, and some of us Westerners call it Mandarin.) --Aghniyya 10:20, 4 May 2009 (UTC)
- The problem is that "Chinese" is ambiguous. Yes, when people say "Chinese", they mean Mandarin, and if they don't mean Mandarin then they have to be clear about that. The fact that "Chinese" is used in translations more than "Mandarin" is a problem here because the approved and de facto language header is the latter. We should never use "Chinese" by itself so what we need to discuss is how to eliminate it. DAVilla 16:53, 4 May 2009 (UTC)
- Well, this is the common practice in Wiktionary at this point, so we would have to go through and change possibly over a thousand entries, which is unlikely to happen. We should focus on getting the translations up.
- Not only is this a distraction, in any case, I still disagree with your linguistic approach here. I'm in a graduate program, and I couldn't see my professors supporting you here. Languages are, remember, socio-cultural constructions, so it's best to follow the universally accepted practice, both in Chinese and western cultures: Chinese means Mandarin (and Mandarin itself is a silly, archaic, Orientalist term for "putonghua"). The PRC constitution says, "The standard spoken and written Chinese language means Putonghua (a common speech with pronunciation based on the Beijing dialect) and the standardized Chinese characters." From there on, the Chinese constitution only refers to Chinese. Likewise, no one buys a "Mandarin-English" dictionary - it's Chinese-English.
- Lastly, when people are searching for a translation from a long list, they will not search for Mandarin; they will search for Chinese. Anything else will confuse them (e.g., think of a native Chinese speaker who will not think of the term "Mandarin"). So let's please put this behind us! --Aghniyya 06:20, 5 May 2009 (UTC)
- You've done a great job of twisting linguistics, a social science that observes human behavior, into an excuse for politics, a cultural tool that directs human behavior. The PRC is a political entity and not a linguistic authority apart from what they can force their schools to teach, the Standard Mandarin that your quotation refers to. It is after all Standard Mandarin Chinese that the quotation refers to, regardless of what it is called by them or by us or anyone else.
- In one sense, Chinese = Mandarin, and in another sense, Chinese is a family of languages. You can argue whether the label should be Chinese or Mandarin or something else, but please do not cross the line into thinking that Mandarin, or what the PRC calls Chinese, is a family of languages, as if to say they're all the same. DAVilla 07:42, 5 May 2009 (UTC)
- I agree with Aghniyya's point. As a native Mandarin speaker (with Min Nan & Cantonese background) I would most likely look for the translation under Chinese instead of Mandarin. I think it is more intuitive to nest Mandarin & other dialects under Chinese instead of having top-level entries (not grouped under Chinese). When I think of the translation, 翻譯成中文 (translate into Chinese) makes more sense than 翻譯成普通話 (translate into Mandarin). --Ccsheng125 01:38, 7 May 2009 (UTC)
- I should also say that this question of languages and dialects comes up in numerous cases, and linguists always decide to let socio-cultural definition lead the way. Otherwise, it's chaos. Shall we list German under "Hochdeutsch"? Or Arabic under "FusHa" or "Modern Standard Arabic"? After all, Arabic and German do NOT refer to Austrian German, Plattdeutsch, or any spoken Arabic form at all (Standard aka classical Arabic has no native speakers). But there is a standard, and everyone knows it. --Aghniyya 06:29, 5 May 2009 (UTC)
- I've already written too much, but I'll also say that even in scholarly journals, Chinese is used to mean standard spoken Chinese, ie, putonghua/Mandarin. --Aghniyya 06:46, 5 May 2009 (UTC)
- I don't argue that. My argument is that it also means something else. Chinese can be an ambiguous term. If here we decide that it means Mandarin specifically, then I'm fine with that, as long as we are deliberate and consistent. Calling Mandarin "Chinese" would mean that the other dialects are not Chinese (i.e. not Mandarin). DAVilla 07:42, 5 May 2009 (UTC)
- Aghniyya has given very good arguments here about the common usage. In any case, at least, in mainland China, the separation of Chinese dialects is not encouraged and not supported by the Chinese themselves. Norwegian and Danish may understand each other but they don't think they belong to the same language but Chinese think of themselves as Chinese and that they speak Chinese, regardless of their dialect. I am keen to add more translations into Chinese but this discussion is not helping. Whatever we change, if we change, it will become inconsistent and would require a lot of rework. Anatoli 12:04, 5 May 2009 (UTC)
Do we have to eliminate Chinese?
No. Current practice sometimes solves this by using * Chinese: ** Mandarin: in translations. However, this is not consistent with the way we handle other names of languages. Languages are sorted alphabetically, not grouped by language family. For instance, the Scandinavian languages (edited) are not only closely related, some are mutually intelligible! But we do not put Danish and Swedish next to each other just because a speaker of one can understand the other.
There are better solutions. As appropriate, we could use * Chinese: ''See Mandarin'' or * Chinese: ''See Mandarin, etc.'' in translations (and probably also * Farsi: ''See Persian''), or we could use * Mandarin Chinese: and adopt ==Mandarin Chinese== as the language header name. I don't really see "Cantonese Chinese" as being necessary, just "Cantonese" should suffice, so this would be a conscious exception to the rule. DAVilla 17:26, 4 May 2009 (UTC)
- I don't like the idea of See X as it just adds clutter, and, assuming every page is formatted the same (which it will be eventually), people only have to find the language they are interested in once. Nesting is not ideological, it just exists to make the page easier for people to follow - so it should aim to do what they expect (I personally would expect to find Mandarin under Chinese if it wasn't under Mandarin, same with Nynorsk and Norwegian). Conrad.Irwin 22:59, 4 May 2009 (UTC)
- That's fair. Personally I would prefer to see * Mandarin Chinese but I wouldn't even care if we simply called it * Chinese providing we got rid of the second indentation, listing the other dialects like * Cantonese in the full alphabetical list. DAVilla 06:43, 5 May 2009 (UTC)
- Aren't the written forms of entries in the different Chinese languages often identical? If so, then why scatter them all over the list of translations? Group them together in a prominent block, and no one looking for a Chinese translation will ever have any trouble finding it. —Michael Z. 2009-05-04 23:49 z
- Nynorsk and Bokmål are of interest only if they are different, perhaps making Bokmål the default makes sense, add Nynorsk if different. I don't see the need for the split if they are identical, same with Chinese. Anatoli 00:07, 5 May 2009 (UTC)
- First of all, no. See A-cai's comments below. Second, it doesn't matter whether they're similar or not. As I pointed out, there are very similar languages that are listed under completely dissimilar names. We do not group any other languages in these sorts of prominent blocks. Why does Chinese have to be an exception? If you argue that alphabetical order isn't ideal for these dialects, then you'd have to be willing to extend that argument to cases where it is much more applicable. DAVilla 06:40, 5 May 2009 (UTC)
- (@DAVilla) grouped by language family - this means maintaining the theory which considers the dialects of the Chinese language to be separate languages... Well, how can two dialects be declared separate languages, when 95% of the words have a common spelling? (not talking about the pronunciations here). For instance, the Scandinavian language are not only closely related - did you really mean to write the Scandinavian language? Even me, a staunch sceptic when it comes to fabricating new languages out of hitherto existing dialects, do not think that Danish and Swedish can possibly be one language, as I have more difficulties when reading Swedish texts and when hearing Norwegian speakers (with my knowledge of Danish) than listening to Swedish users or reading Norwegian bokmål. In case this was an inadvertent misspelling of yours, then the apt example is not Scandinavian languages, and Anatoli already pointed out the more applicable Norwegian Bokmål-Norwegian Nynorsk or Flemish dialect of Dutch-standard Dutch. As they are listed under one header and when there is no spelling difference, not even mentioned to be two variants, the same approach should apply to the Chinese language: * Chinese: xxx (pinyin: xxx, /*other pronunciations*/) . It is not Chinese which should be eliminated, but the term Mandarin, transforming the whole issue merely to a pronunciation issue. Well, for those 5%, where there is any difference in spelling, perhaps we should use the terms Mandarin, Cantonese and so forth, but under the header of the Chinese language. The uſer hight Bogorm converſation 09:54, 5 May 2009 (UTC)
- I have to correct a common misunderstanding here. It is simply not true that words between all Chinese dialects have a common spelling 95% of the time. Here are some figures (quoting from: w:Min_Nan#Mutual_intelligibility), Mandarin and Amoy Min Nan are 62% phonetically similar and 15.1% lexically similar. The reason for the misunderstanding is that many of the people who speak a dialect other than Standard Mandarin often use Standard Mandarin as a "lingua franca" written language. This is not unlike the relationship between Modern Standard Arabic and other varieties of Arabic. -- A-cai 10:48, 5 May 2009 (UTC)
- A-cai, could you please elaborate the meaning of "15.1% lexically similar", it seems really too small. I saw this in the Wikipedia article. Not sure what it means here and what measurement of similarity was used. Many phrases in Min Nan, when written in Chinese characters are comprehensible even for my Chinese, even if the word order and word choice may differ from the standard Chinese. Some most common words, although their number is very small, like in Cantonese, are different from Mandarin. BTW, the Arabic translations have * Arabic first, followed by **dialects, without specifying * Modern Standard Arabic or * Classical Arabic. * Mandarin seems to be denied the status of being standard Chinese by some of you guys. Anatoli 11:34, 5 May 2009 (UTC)
- Could be a typo (from the original cited article). I wonder if it's supposed to be "51.1%" lexically similar"? That would be a closer match to my Swadesh list comparison (see below). -- A-cai 02:30, 6 May 2009 (UTC)
- Dungan is written in Cyrillic. Thus your point is moot. -- Prince Kassad 12:19, 5 May 2009 (UTC)
- Dungans don't call themselves Chinese, they call themeselves Dungans or Tungani, even if their language is comprehensible to Mandarin speakers and especially Huizu. Dungans didn't have a chance to learn proper Chinese. Mandarin and other dialects can be written in different scripts but they are normally not. Min Nan is sometimes written in a romanised script to show the pronunciation difference. Not sure if ** Dungan should appear under * Chinese, perhaps it could and should. Dungan can be written in hanzi for native Chinese words to show the variant spelling as with Serbian Roman/Cyrillic - хуэйзў йүян / 回族语言 / Huízú yǔyán. Anatoli 12:37, 5 May 2009 (UTC)
- Indeed the sorting is not clear. I currently sort Dungan under Chinese, but if people prefer it to be separate, that's possible too. -- Prince Kassad 12:45, 5 May 2009 (UTC)
- (By the way, pinyin is a transliteration or romanization. Calling these pronunciations could confuse people when adding translations in other languages.)
- This isn't just a pronunciation issue. Saying that the Chinese dialects are basically equivalent except for grammar is like saying that German and English are essentially the same except for word order. If you're thinking more along the lines of British vs. Australian English, pronunciation differences exist between the Beijing, Qingdo, and Xuzhou dialects of Mandarin. You would think that within a major branch of Chinese like Wu there would be less variation. However, many Wu dialects, apart from Taihu, are not mutually intelligible. Hui, which can be Wu or Gan depending on who you ask, has a high degree of unintelligibility even from county to county. These are where the pronunciations differences lie. It makes little sense to say that these branches, which have variation even within themselves, differ only in pronunciation from other branches. Between branches like Mandarin and Min Nan there are even false friends such as run/walk.
- I think this objection to splitting langauges that might in some cases use the same characters is very odd. Many words like animal, taxi, mango, and international are the same spelling and meaning across very different langauges. The more similar the language, the more crossover, as with the romance languages. 72.177.113.91 17:26, 5 May 2009 (UTC)
This whole argument about what constitutes a language and a dialect is utterly boring and moot for linguists. Everyone agrees that even linguistically separate languages, like Egyptian Arabic and Standard Arabic, can be considered dialects of the same language if the speakers define it that way. Likewise, linguistically unitary languages like Danish and Norwegian can be separate if the speakers so choose. "A language is a dialect with an army and a navy," as Max Weinreich said. Let's use the socially recognized designations for languages and dialects. Let Swiss German be a dialect of German, Wu a dialect of Chinese, and Moroccan and Egyptian a dialect of Arabic, and Mandarin Chinese is standard Chinese. Now, the question is, how should these things be listed? Dialects could be listed as alphabetically separate from the languages themselves. This is more convenient for writing entries than having to manually indent the entries. However, I would still argue that dialects like Wu and Egyptian should be indented next to their standard languages. Why? Because it's more convenient for users. I myself am a very serious learner/speaker of Arabic and Arabic dialects (which are linguistically speaking separate languages, but not socio-culturally). If I am looking at how to say a word, I tend to assume that the dialects won't be present on the list. If they are indented next to the standard, it's right there for me to see. --Aghniyya 18:12, 5 May 2009 (UTC)
- Interesting that no-one argues that Arabic entries should appear under * Arabic, followed by possible dialects but with * Chinese, we have this argument. The entries followed * Arabic are of FuSHa, are not called * Modern Standard Arabic or * Classical Arabic, the language not usually used in common speech but Mandarin - the official and standard Chinese language, needs to be disputed here.
- Anyway, one point that A-cai mentioned that Min Nan is "15.1% lexically similar" to Mandarin. Japanese, Korean and Vietnamese are said to have between 40% to 60% of common vocabulary to Chinese dialects, of course pronounced differently but there is a pattern, how can a Chinese dialect be more remote from Mandarin than a foreign language? There is something wrong in that Wikipedia article.
- In Wikipedia, they use multiple templates providing jiantizi/fantizi + different pronunciations - pinyin, Yale and pe̍h-ōe-jī to represent Mandarin, Cantonese and Min Nan. A template with different optional parameters would do the job, in case when the Chinese spelling is the same. See Bogorm's comments. Anatoli 01:45, 6 May 2009 (UTC)
Anatoli 01:45, 6 May 2009 (UTC)
- There is a common misunderstanding that Chinese words are mostly written with the same Chinese characters, regardless of dialect, but pronounced differently. Intuitively, I know this not to be the case, and have attempted in several earlier posts to cite online research to back my claim. I decided to take a different approach for this post. Let's assume that we were to label everything as "Chinese" in the translation sections, except in cases where there is a divergence (as was suggested by another contributor). What would happen?
- I will use Mandarin and Min Nan, only because those are the two dialects that I speak. I'm not about to compare the entire lexicon of both languages, for obvious reasons. However, I can compare the Swadesh lists for Mandarin and Min Nan, which should provide sufficient insight for the purposes of a Beer Parlour discussion. Although there are 207 words in the Swadesh list, it actually requires a total of 295 individual Mandarin words to account for all of the senses of the 207 English words. It requires 307 Min Nan words to account for all of the senses of the 207 English words. For example, the English word "not" is expressed with five different words in Min Nan and three different words in Mandarin, depending on the sense of the word "not" that you want to convey.
- In the above hypothetical, I would only label as "Chinese" those words that are written with identical Chinese characters and are used in the exact same way in both languages. For example, the word for "mountain" in both Mandarin and Min Nan and is 山. Furthermore, the sense meaning of 山 is identical in both. The only thing that is different is the pronunciation. As such, 山 would qualify for the "Chinese" label in the above hypothetical. In the translation section, you might see something like:
- large mass of earth and rock
- Chinese: 山
- Mandarin: shān
- Min Nan: soaⁿ
- Chinese: 山
- large mass of earth and rock
- However, 怎樣 meaning "how" would not qualify, despite meaning "how" both in Mandarin and Min Nan (12 out of 149 "matches" fall into this category, and are thus "disqualified" from my calculations. The final number of "matches" is therefore 138). The reason is that while 怎樣 is the informal word for "how" in Mandarin, it is regarded as a rather formal term in Min Nan. The equivalent word in Min Nan to 怎樣 is 按怎. As such, this would be a divergent case, and would appear in the translation section as:
- Ok, so taking all of that into account, what did I find? It turns out that 138 words (not counting the 12 "false" positives) were a match between Mandarin and Min Nan. That works out to 44.62% (138/307, 307 being the total number of Min Nan words needed to represent the 207 English words in the Swadesh list). In other words, if one assumes that the Swadesh list is a rough representation of the language as a whole, you would expect to see a common "Chinese" label 44.62% of the time. The other 55.38% of the time, you would require separate "Mandarin" and "Min Nan" labels.
- In case you want to try it yourself, I used the Appendix:Amoy Min Nan Swadesh list and the Appendix:Mandarin Swadesh list for my stats. -- A-cai 02:15, 6 May 2009 (UTC)
- I've read your reply in full but will only give a quick reply with questions, sorry, will get back later if I can. Your calculation (44.62%) is based on the Swadesh list? This list consists of the very basic and the most common words in a language - pronouns, question words, quantifiers. These are the words that mostly differ between Mandarin and dialects. I have almost no knowledge of Min Nan but I can judge by my exposure to Cantonese. Wouldn't your 55.38% (of Swadesh list) only convert to a couple of hundred words out of many thousands Chinese words? Besides, 怎樣 is not foreign to Cantonese or Min Nan speakers, am I right? Although you'd prefer to write 按怎 when using Min Nan? Let me explain a bit, in Cantonese, the word for "come" is 嚟 (lei4) but common Chinese 來 is also used as a cognate. Isn't it the same in Min Nan, do you at times write 怎樣 but say án-chóaⁿ? Would you a different pronunciation in a formal Min Nan, more similar zěnyàng? Anatoli 05:43, 6 May 2009 (UTC)
- Yes, the 44.62% is based on the Swadesh list. I agree that if you were to do a much larger sample, the number might increase. However, I don't think it would increase as dramatically as you might think.
- In the case of 怎樣, I understand your question, but that is a different phenominon. 怎樣 (chóaⁿ-iūⁿ) is a legitimate Chinese word in Min Nan, but is not used in the same way as 怎樣 (zěnyàng) in Mandarin. What you're talking about is spot translating a Mandarin word into Min Nan. For example, "how much" in Min Nan is 偌儕 (jōa-chē), but is commonly written with the Mandarin characters 多少. If I were to pronounce 多少 in Min Nan, it would be to-siáu, but would be met with strange stares, if I tried to use it in Min Nan. -- A-cai 11:02, 6 May 2009 (UTC)
- There seems to be little written material in Min Nan with Chinese characters but if it is written in Chinese characters, it will be very comprehensible (especially serious topics) to Mandarin, Wu or Cantonese readers. The small number of incomprehensible but frequent words may impede the understanding + some false friends. I would be interested to see a mutual intelligibility analysis of larger texts, not of selected, specifically dialectal words. Modern written Cantonese, Wu and Mandarin are mutually very intelligible. Anatoli 06:12, 6 May 2009 (UTC)
- One of the most lucid articles that I have found online on this subject can be found at: http://www.glossika.com/en/dict/faq.php#18. -- A-cai 11:02, 6 May 2009 (UTC)
- The last item, no. 19, should confirm some of the statements here. It's supplemented by a first-hand account as well, while the rest of the information, though interesting, is more analytical than narrative-based. Chinese speakers can have a multitude of their own fist-hand experience by listening to the recordings at the bottom of this page... at least in theory. They don't download for me. DAVilla 18:15, 6 May 2009 (UTC)
How can we make editors aware?
By agreeing to a format so that an example can be listed explicitly in the entry layout and other help pages.
By splitting Wiktionary:About Chinese into several pages so as to reinforce the idea that these dialects are treated separately.
By using the correct term in assisted edits and otherwise running bots to clear up the current mess, since many contributors just copy or do as they see. DAVilla 17:27, 4 May 2009 (UTC)
- Bots to clean up mess is fun, on the condition that everyone can agree exactly which changes are to be made. Conrad.Irwin 22:59, 4 May 2009 (UTC)
- I support retaining Chinese as the main header for translations, which should contain the standard Chinese spelling. The definition of what is Chinese language stems from the Chinese themselves. There is very little language separatism in China, why should we promote it? The formal or standard writing is almost identical for all Chinese dialects. The benefit of having just Chinese is that dialects can be added ** Cantonese, **Min Nan as nested, if somebody bothers to do but it's important to have the Mandarin entry. If we add ** Mandarin to each * Chinese
- There are a lot of entries to change. it seems using the word "Chinese" is popular with many editors.
- We are not using space efficiently - there will always be a blank line
- Mandarin IS the standard Chinese. The big difference (especially in separate words) is mainly in the pronunciation.
- Dialects are often added for pronunciation purpose only. They use the same character, e.g. Indonesia can be written as 印尼 in Chinese, pronounced Yìnní in Mandarin and Ìn-nî in Min Nan. Min Nan is not a written language, like many Chinese dialects are, they write in standard Chinese (Mandarin) but may pronounce words the Min Nan way. Hong Kong TV anchors have their speeches written in Chinese Mandarin, they read it out loud in Cantonese.
- Chinese dialects can be grouped together, if entries are added and they can be cross-referenced. My preference is to have * Chinese (** dialect 1, ** dialect 2), omitting ** Mandarin altogether.
- Even the colloquial, informal Cantonese only differs by about 5% from Mandarin, many words from Cantonese do penetrate standard Mandarin if they are used too often in writing. The separation between traditional/simplified applies to dialects as well, although some are under assumption that Cantonese is always written in traditional characters. Cantonese speakers in Guangdong province use simplified characters to write in their dialect. Anatoli 23:01, 4 May 2009 (UTC)
- Please see Appendix:Sino-Tibetan Swadesh lists for a side by side comparison of basic words in some of the more well known Chinese dialects. -- A-cai 00:49, 5 May 2009 (UTC)
- Thanks, A-cai. This is very useful and interesting. I do read about dialects, although I am not studying them now. So you support the idea of separate translations for each Chinese dialect? Even in your list all dialectal entries are under the same Chinese characters, even if some of them are only used in modern dialects (e.g. 伊 also has the Mandarin reading and the meaning is known but not currently used). As I suggested before, the rare cases where they are different and don't overlap, like 佢 and 他 can be listed together (see he. In any case, standard Cantonese will use 他 in formal writing, so I would prefer to write: * Chinese 他 (tā), ** Cantonese 他 (formal writing), 佢 (colloquial) with pronunciations. In this case, 他 is common for any Chinese, the dialectal form may not exist, even if does, the Mandarin form may still be used and is known. Anatoli 01:33, 5 May 2009 (UTC)
- I can't see any other way to do it. I tried to have everything labeled as "Chinese" when I first started two years ago. It became quickly apparent that it just wasn't going to be a sustainable model, if we wanted to include anything besides Standard Mandarin. I was initially in favor of treating each mutually unintelligle Chinese dialect as a separate language, and listing them in the translations accordingly. However, this proved to be unpopular with many of our users. It seems from some of the above posts, that there is still resistance to the idea. The *Chinese **Mandarin **Min Nan etc model was a compromise solution. I'm not sure that we will ever be able to come up with a solution that will please everybody. However, the compromise solution mentioned above has more or less held for the last two years. -- A-cai 01:53, 5 May 2009 (UTC)
- P.S. the varieties of Chinese can be more varied than you might initially think. For more information, see: Varieties of Chinese. -- A-cai 01:57, 5 May 2009 (UTC)
- The situation has somewhat changed with the introduction of assisted translations, which Conrad.Irwin has kindly developed. If the nesting can be fixed then it's fine, otherwise, all translations can be done quickly, except all Chinese translations will have to be done manually, which is sad.
- My other point is, how many Chinese dialect editors do we have? The grammatical differences are irrelevant here. The differences in the written form are low. I took part in editing that article and others in Wikipedia. Anatoli 02:12, 5 May 2009 (UTC)
- As a general rule, please don't let what software makes "easy" the right thing to do. I hope to have support for nesting this week, it requires writing four further types of 'edits' (adding a new nested section with heading, adding a new nested section (using *:) to a heading that has translations, adding a new *: and adding a new ** translation to nested lists that already exist), of which the first two are done, I'm now struggling with how to sort these nested languages, as presumably "Old " should come before "Middle", but otherwise I think alphabetical works well enough. For Chinese is this the case, or do we want to always put Mandarin first, or something yucky? Conrad.Irwin 08:36, 5 May 2009 (UTC)
- In this model that you propose, is "Chinese" supposed to mean "Mandarin", or is "Chinese" supposed to mean a family of languages? What this hierarchy would seem to imply is that Mandarin is the only real Chinese language, and that the other dialects are offshoots of it. In fact major branches like Hakka bear more resemblance to Middle Chinese, and Min not even to that!
- As to your TV anchors, this is the result of schooling. Cantonese can be written, but because this is not easily understood by speakers of Mandarin etc., in formal writing Cantonese speakers use a standard written Chinese. As a result, it is much easier for Cantonese speakers to learn Mandarin than for speakers of Mandarin to learn Cantonese.
- Your arguments entirely gloss over the very real grammatical differences. It's like saying German and English are essentially the same except for word order. DAVilla 09:18, 5 May 2009 (UTC)
- A good compromise could be to accept Chinese (zh) (after all, it's a code used by Wikipedia and in interwiki links) and Mandarin, Cantonese, Wu, etc (they all have their own ISO codes). In the same translation table, or in the same page, the same word could be present in both Chinese and Mandarin, for example. But it could also be present only as Chinese, or only as Mandarin, depending of options taken by contributors. Languages would be sorted normally, according to their names. I'm aware that this would allow duplication and that this is not a satisfactory solution, but this might be the simplest solution, information provided would not be wrong, and it would be easy for all readers to find what they look for. Lmaltier 10:15, 5 May 2009 (UTC)
- That's what I a have been suggesting but DAVilla disagrees. If Mandarin can't be made the default and be regarded as simply * Chinese (if dialects are missing), then let them be nested but I don't like extra work and not looking forward to manually adding * Chinese \n\t ** Mandarin to each translation I make. This argument must have happened a few times here and if the majority of the existing translations use simply * Chinese, it indicates what their preference was. The word Chinese is simply a more common English name for the standard Chinese language than Mandarin. Anatoli 11:48, 5 May 2009 (UTC)
- FYI: it doesn't indicate "what their preference was"; it just happened by default because (as A-Cai notes) we were not properly distinguishing the languages in the Chinese group until 2 1/2 years ago. Robert Ullmann 12:20, 5 May 2009 (UTC)
Please people. This is not complicated, and there is only one problem that needs to be resolved (as David identified at the top): we have a substantial number of entries that have only "Chinese:" in the translations sections that need to be corrected to "Mandarin:" (or separated into "Mandarin", "Cantonese", etc). Otherwise people will copy them (and/or confuse themselves with "needing" to change the zh template or something). This is the only thing that "needs to be fixed".
The zh code should not be used anywhere with the wiktionary; language "Mandarin" is cmn (and so forth). The fact that WMF uses "zh" in the domain name(s) for Mandarin (and zh-min-nan for Min Nan, zh-yue for Cantonese) is not something users or editors need to or should see. The {{t}} template converts (cmn->zh etc) internally; Tbot and Interwicket know other details. (We probably should get rid of template {{zh}} entirely.)
As to grouping under Chinese: that is a separate issue, and whenever we decide something, it will just get added to AF's sort algorithm, so you don't need to "fix" it. For now use:
* Chinese: ** Mandarin: ** Wu:
or the individual language lines as you want. (I.e. if you are adding Mandarin with the acceleration (or not), add code "cmn", and don't worry about the "grouping".) If you do group them, note the ** which says the sub-line is a full language name, not some other qualifier, which always uses *: Robert Ullmann 12:16, 5 May 2009 (UTC)
- In order to come up with an idea and not only appear to be cavilling at the Mandarin separatistic practice, my suggestion for the entry layout is:
- 1) When there are no spelling difference (vast majority of cases)
* Chinese: [[xxx]] (transliteration in Pinyin for Mandarin, transliteration in [[:w:Jyutping|Jyutping]] for Cantonese, ...)
- 2) spelling difference:
* Chinese: ** Mandarin:[[xxxM]] ** Cantonese:[[xxxC]]
- I do not see any reason for the cmn templates, because I see no reason for rejecting Chinese as a header followed by clarifications concerning the regional pronunciations/transliterations systems in brackets and italicised. Thus, my opinion is that a bot converting all Mandarin entries to Chinese with a (Mandarin) note would be more appropriate instead of vice versa. Such note would be needful only in the pronunciation sections and before the romanisation, with meaning and spelling intact. In the exiguous minority of cases where spellings differ, it may also be applicable before the meaning (of the regional dialects of cours, not before the meaning in standard Chinese). The uſer hight Bogorm converſation 21:35, 5 May 2009 (UTC)
- A-cai responds to this point when he mentions the Swadesh lists in the section above. 72.177.113.91 05:11, 6 May 2009 (UTC)
- Mandarin is more specific than Chinese, but due to Widespread use of "Chinese" to de facto mean "Mandarin", I consider that both form should be allowed in translations. For sectional entries, perhaps ==Chinese== should have a redirect to ==Mandarin==. Or should we consider ==Chinese (Mandarin)== as a compromise? I have not seen dictionaries being "Mandarin-English" or vice versa.--Jusjih 03:19, 7 May 2009 (UTC)
- A-cai responds to this point when he mentions the Swadesh lists in the section above. 72.177.113.91 05:11, 6 May 2009 (UTC)
Reframing the question
Putting aside the distinction between the labels that describe the Chinese languages, can we at least agree to use the same labels in the level two language headers as we do for bulleted translations? It doesn't make sense to click on a translation for * Chinese, as at present most are simply labeled, and not find a section called Chinese on the next page. Considering that most of the terms are defined under a ==Mandarin== heading as policy dictates, this is a big discrepancy. I don't care if we have to change one or the other, it's going to be a big undertaking, and we may as well take it. Better sooner than later. I've stated my preference above, but ==Chinese== would at least be consistent. And heck, if we have to change every single one to "Mandarin Chinese" or the like, all the better as long as this is settled. DAVilla 05:42, 6 May 2009 (UTC)
- I agree but, if both Chinese (zh) and Mandarin (cmn) are accepted (in translations as well as in language headers), this would also work. Isn't compatibility with WM language codes at least as important as compatibility with ISO? Shouldn't all WM codes (e.g. zh) be accepted, even when they conflict with ISO (e.g. als)? Note that the only issue I'm raising is priority between conflicting compatibilities (I know that the best and most complete list is ISO, but I think that compatibility with Wikimedia is very important). Lmaltier 06:43, 6 May 2009 (UTC)
- I'm not sure I understand. How can both "Chinese" and "Mandarin" be accepted? Wouldn't we have to pick one or the other? The words that are listed under * Chinese are de facto Mandarin Chinese. Now, I don't mind calling them just "Chinese" or whatever else we may decide, as long as it's consistent on this project. WM codes really have very little to do with this except that people seem to like using zh when they should be using cmn. DAVilla 07:14, 6 May 2009 (UTC)
- I don't mind calling them just "Chinese" - that is great. I agree with calling them consistently Chinese, but not with calling them consistently Mandarin. People like that which is the established and usual practice and have their reason for that. The uſer hight Bogorm converſation 07:33, 6 May 2009 (UTC)
- Again, step back for a minute from which label is actually used. Do you agree that, all else being equal, we should be deciding just one question, of which label to use, rather than two questions, of which label to use in translations and which label to use in language headers? If it's the latter then there are inconsistencies. (I know your first preference is to have both be "Chinese". For your second preference:) Would you rather have different terms used depending on where the label is placed, so that for instance a user clicks on a "Chinese" translation but has to scroll down to a "Mandarin" definition as is current practice, or would you rather have both the translation and the language heading correspond, labeled as decided by the community, which might mean seeing "Mandarin Chinese" in both places? DAVilla 17:17, 6 May 2009 (UTC)
- Of course there is no use in labelling the translation and the entry differently. Having seen the translation labelled as Chinese, the reader expects to discover an entry labelled Chinese as well and that is also what I expect. As the comparison with varieties of Arabic or (the more familiar for me) Norwegian bokmål and nynorsk shows, one should use either Mandarin Chinese in the caption (when spelling differences exist) or rather a header Chinese and a (Mandarin) / (Cantonese) / ... note and not these subordinated designations (dialects) as headers. Ivan's approach with Ekaviana and Ijekavian Serbo-Croatian is exactly what I mean (see hteti/htjeti). The uſer hight Bogorm converſation 21:16, 6 May 2009 (UTC)
- Again, step back for a minute from which label is actually used. Do you agree that, all else being equal, we should be deciding just one question, of which label to use, rather than two questions, of which label to use in translations and which label to use in language headers? If it's the latter then there are inconsistencies. (I know your first preference is to have both be "Chinese". For your second preference:) Would you rather have different terms used depending on where the label is placed, so that for instance a user clicks on a "Chinese" translation but has to scroll down to a "Mandarin" definition as is current practice, or would you rather have both the translation and the language heading correspond, labeled as decided by the community, which might mean seeing "Mandarin Chinese" in both places? DAVilla 17:17, 6 May 2009 (UTC)
- Okay, in that case the translations are labeled as Serbian or Croatian, but the language header is Serbo-Croatian. I guess if someone followed a translation for "Chinese" then they would be able to find Mandarin Chinese on the next page. That doesn't sound unreasonable. DAVilla 02:18, 7 May 2009 (UTC)
- My proposal is to allow both, provided that information provided is not wrong. This would lead to duplication (and the Chinese version might probably include more information in some cases), but this would be compatible both to ISO and to WM codes, and everybody would be happy. Lmaltier 11:59, 6 May 2009 (UTC)
- The real answer is that this will most likely not be resolved one way or the other until Wiktionary attracts more Chinese speakers to the project. In the last 2+ years, I have been the only consistant contributor of Chinese words. As I tried to explain above (in great detail), "Chinese" is simply not workable as a label, unless, that is, we equate "Chinese" in every instance to Standard Mandarin. Trust me, I've tried. Again, if a word is used in one dialect but not another (as is the case as much as 50% of the time between some dialects of Chinese), how would you deal with it, if everything is labeled as Chinese? I don't mind "Chinese Mandarin," but again, that has been voted down in the past. Just so everyone is aware, this is not the first time that we've had this kind of lengthy discussion on Beer Parlour about this subject. Over the last two years, I have participated in least three or four similarly themed discussions (go back and check, it's all archived :). -- A-cai 22:54, 6 May 2009 (UTC)
A compromise proposal
The label CHINESE would be taken to mean Mandarin Chinese. As a statement of general principle, any translation that is different from that would be labeled as such and alphabetized as with any other language. Cantonese comes before Catalan and Cebuano, Hakka after Haitian Creole. None of these would be called Chinese under any heading. Aside from Old Chinese and Middle Chinese, the only translations that could be labeled Chinese are the Mandarin translations, which need not say Mandarin at all, depending on how the community wishes to treat that language. In other words, each language heading corresponds with a row in the translation table. A possible exception to this are the Min languages, the bifurcation of which is an issue that should be decided separately. Likewise any proposals to isolate variants of Mandarin such as Dungan and Jin would be addressed separately. This is a compromise because the branches of Chinese would retain their own names, allowing "Chinese" itself to remain in use for Mandarin translations without ambiguity. DAVilla 03:21, 7 May 2009 (UTC)
- Doesn't look like a compromise to me. In my opinion, * Chinese ** Mandarin ** Cantonese ** Min Nan, etc. (nested) is far better, only awkward for the moment. You are separating the dialects, which was your original idea, where is the compromise? Didn't you already mention that you were agreeing with having Chinese as the default (meaning Mandarin) with others nested as they get added, eg. * Chinese (meaning Mandarin) ** Cantonese ** Min Nan, etc. (nested). Also, Chinese Mandarin is better than Mandarin Chinese, users start by searching for Chinese translations, not Mandarin. This option is not ideal either. I prefer the status quo, currently we have nested or just * Chinese if dialects are missing. Anatoli 03:45, 7 May 2009 (UTC)
- The dialects have always been separated. They have had their own language headers. They have their own bulleted rows in translations, though oddly grouped together. When only "Chinese" is listed it is invariably the Mandarin translation alone. I am not separating the Chinese languages, I am ungrouping them just the way we ungroup every other language family: Serbian and Croatian, the Scandinavian languages, the Arabic languages, etc.
What does "Mandarin Chinese" versus "Chinese Mandarin" have to do with anything? This is a distraction I thought I'd separated out for the moment. It's a good idea, yes, but not on point. How should the translations be structured? - I did not mention that I agreed to have Chinese as default. I mentioned that it would be my second preference, as better than status quo. Conditional to that agreement was a distinction between "Chinese" meaning Mandarin and "Chinese" meaning the language family. My first preference is to simply call it Mandarin or Mandarin Chinese. You on the other hand seem to like status quo, inconsistent as it is with the choice of Mandarin as a language header, probably the only standard we have agreed upon to date. Where is the compromise in your proposal? In case it is not clear to you, status quo is contrary to policy.
{{zh}}was not a mistake, it was a deliberation. - Let me tell you what you are effectively doing by confusing the two meanings of "Chinese". You are playing into the PRC's politically motivated game to stamp out any sort of Chinese that is not Mandarin. This is contrary to Wiktionary's "all words in all languages" vision. Essentially you say that the other languages of China are imperfect because they are not the true Chinese, equating any so-called dialect with Chinese, and Chinese with Mandarin, and therefore making any dialect a variant of Mandarin. They are not. They are better understood as independent variants descended from Middle Chinese, and Min not even that. Mandarin is not representative in any linguistic way.
- Pick one meaning of "Chinese" and stop playing these word games. If you think "Chinese" should mean Mandarin, as was argued above, then you must conclude that the other branches are not to be grouped under a Chinese heading. If you think that "Chinese" should mean the language family, then you must conclude that the correct label for the translations you're adding should include the word "Mandarin" or the like so as to distinguish from the other branches. Now that doesn't say they must be ungrouped, but it does say that * Chinese: by itself would be invalid. If you want to use simply that in translations, as you've said above, then that would equate Chinese with Mandarin, which is why the other languages could not use the "Chinese" label, per this proposal.
- Status quo is inconsistent, only serving to confuse the issue. It adds an unnecessary level of complexity to the layout, one we have lived with to date. However, even that has not been followed by Mandarin translators who add solely under the "Chinese" banner. The only consistent way to possibly have all the Chinese languages under the same name is if they all had the same level 2 language header, with dialectical tags in the definition lines. This is probably the view that the PRC would take, but in practice it is a preposterous proposition because the languages are simply too different. The policy we have for structuring translations must extend from the policy we have for listing entries in the first place. This is why in the end yours is a losing argument. DAVilla 09:23, 7 May 2009 (UTC)
- The dialects have always been separated. They have had their own language headers. They have their own bulleted rows in translations, though oddly grouped together. When only "Chinese" is listed it is invariably the Mandarin translation alone. I am not separating the Chinese languages, I am ungrouping them just the way we ungroup every other language family: Serbian and Croatian, the Scandinavian languages, the Arabic languages, etc.
- I'm really being too negative. To address your point of "Chinese Mandarin" vs. "Mandarin Chinese" etc., my position is to yield that to you. It's not part of the proposal explicitly, but it should be. Pick your favorite one. That's the compromise. You get to pick what you call the dominant Chinese language, we get to pick what to call the others.
- Personally it's not the duplicity of "Chinese Cantonese" which I dislike in the * Chinese ** Cantonese nesting, it's the nesting itself. Ungrouping gives you the advantage of calling the langauge whatever you like. The alternative to this proposal is to group (my compromise), but then you would have to call it Mandarin (your compromise). That was what A-cai et al. had settled upon earlier, but it simply hasn't been followed. The result? Chinese translations and Mandarin definitions. And that's why we're here. DAVilla 10:04, 7 May 2009 (UTC)
- I'll agree to nesting, even if it's awkward - * Chinese, followed by all dialects (if the translation exists), including ** Mandarin and including cases where different hanzi are used or hanzi are not known/provided. A-cai and others said it worked as a compromise before, suitable for many others. I have no energy right now to respond to your comments about the political PRC games but I just say I don't want to any dialects but feel they need to be shown together. If this is OK, perhaps we should make a final vote and see if there are still strong objections. Anatoli 11:23, 7 May 2009 (UTC)
A modest request
I have no strong opinons in the above discussion about labelling Chinese. Whatever decision is reached will be fine for me. However, I do request that the decision be clearly expressed and illustrated in WT:AZH (Wiktionary:About Chinese), so that those of us who patrol will know what format is considered standard, and what formats need modification. --EncycloPetey 02:57, 9 May 2009 (UTC)
|
- Before we go any further, please everyone take a look at Sinitic languages, if you have not already done so. It actually does a pretty good job of mapping out the languages that are mutually incomprehensible. A while back, I picked the word child in order to illustrate this in a way that the average reader could comprehend. If one were to base the breakdown on mutual incomprehensibility, child would look something like (in part):
- Chinese:
- Cantonese:
- Mandarin:
- Min Nan:
- Gan:
- Nanchang: 細鬼/细鬼 (IPA: ɕi kui)
- Hakka: 細人仔/细人仔 (se55 ngin11 e31)
- Chinese:
- The reason it does not look like the above in Wiktionary (besides not having enough people to add the words) is that ISO-639 does not have language codes for all of these (according to my understanding, this will be fixed in a future release of ISO-639). I am open to the idea of equating Chinese in every case to Standard Mandarin, but that would still leave us with something like:
- In other words, the "prestige" dialect of each subdialect family would be equated to a top level tag. -- A-cai 01:07, 11 May 2009 (UTC)
- Although there are many dialects and subdialects of Chinese, can we limit the number for the sake of the translations being user-friendly? Otherwise, the translations will have a big article attached on all the Chinese dialects. A-cai, how likely is it that we will need translations into Tianjinhua vs translations into Chinese Mandarin. If we deal with Cantonese specifically, can we limit it to standard (prestige) Cantonese and leave Hong Kong/Guangzhou differences in quotes? There are too many issues with Chinese translations - tradional/simplified, PRC vs Taiwan standard, major and minor dialects/subdialects. Can the appendixes deal with the varieties, so that we limit Chinese translations to the highest level and most prestigious dialects? Perhaps, using this map as a guide? Map of Chinese dialects, even if we add some disputed varieties or use different preferred names. The differences between subdialects can be great but do we need to show all possible variants? Anatoli 04:27, 11 May 2009 (UTC)
- The decision about what to include, and how to include it, is up to all of us. However, if English Wiktionary's goal is to document the English translations of every word in every language, then we must be clear about what we define as a language. My criteria for calling something a distinct language is intelligibility. British and American English are variants of a single mutually intellible language. German and English are two distinct languages. I think words from the same language should be located in the same place. For the purposes of this discussion, let's define, for a moment, the "same place" as the same line in a translation table. For example, if English were hypothetically one of the foreign languages here, you would see something like:
- A rubber or plastic device imitating nipple that goes into a baby’s mouth, used to calm and quiet the baby.
- English: (United States) pacifier, (Britain, Australia, New Zealand) dummy, (Canada, Ireland) soother
- German: Schnuller
- A rubber or plastic device imitating nipple that goes into a baby’s mouth, used to calm and quiet the baby.
- Here are a few more Chinese examples that distinguish between variations within a language, and entirely separate languages. Again, since Min Nan and Mandarin are the two languages that I speak, I will use those two:
- Here is another:
- And finally:
- I hope this clarifies the situation. I just want everyone to be absolutely clear about exactly what we're voting on. -- A-cai 11:22, 11 May 2009 (UTC)
- Whether it is a language, dialect, or subdialect, if it represents how a particular group of people would say it, then it belongs as a translation somewhere in the table. Our ultimate goal is to fully populate those translation tables. This is where the words belong, not in an appendix. DAVilla 05:56, 13 May 2009 (UTC)
Votes
- 2 because I don't want to see e.g. sub-dialects of Mandarin proceeded by ***. DAVilla 05:23, 10 May 2009 (UTC)
- 1 for me, as Chinese is what i would look for in the meaning of a term. However, i have no strong objections either way. i speak a number of dialects, including Hokkien, Teochew and Cantonese, and feel that they come naturally under Chinese, rather than Mandarin. This is my humble opinion (i could be very wrong), as i can't follow some of the arguments laid out here. Psoup 15:27, 11 May 2009 (UTC)
- Just to clarify, under either method Mandarin entries would be found under C for Chinese. This may be C as Chinese > Mandarin if not simply Chinese, but never under M for Mandarin, as there seems to be quite a bit of objection to that.
- The question is mainly how the other dialects would be listed. Is Hokkien under H and Teochew under T (or maybe M for Min Nan), or would these but under C as well, for Chinese > Hokkien and Chinese > Min Nan > Teochew? DAVilla 05:33, 13 May 2009 (UTC)
- i feel that the Chinese dialects (such as Hokkien) should fall under Chinese. This will help structure the dialects and sub-dialects. For example, there are sub-dialects of Cantonese, such as SayYup (i was born into a SayYup-speaking family), and this should fall under Chinese > Cantonese > SayYup. In other words, SayYup should not be under S. To look up a word in SayYup, i would logically look up the written form in Chinese, and then the phonetic form in SayYup. The other way around does not seem logical to me. (Incidentally, the phonetic differences between SayYup and Cantonese is probably greater than that between Cantonese and Putonghua, and a native speaker of Cantonese in Hong Kong will probably not understand SayYup. However, such a person will be able to find the written word in Chinese, and then drill down to the word in SayYup, if it has been created in Wiktionary. ) Psoup 03:36, 14 May 2009 (UTC)
- I am neutral on the subject, with two caveats:
- I am opposed to lumping every Chinese dialect together under one language header called "Chinese."
- If we can't reach broad consensus, I'm in favor of maintaining the status quo. -- A-cai 11:55, 10 May 2009 (UTC)
- 1. What is the status quo, A-cai? What structure are suggesting if, for example, you add a new translation? We have translations under simply * Chinese, under * Chinese ** Mandarin and sometimes traditional and simplified on separate indented lines.
- There shouldn't be any *** under dialects of Mandarin or Cantonese, otherwise, it will be a mess and we won't help anyone wanting simply to find a word translation into Chinese. The non-standard Mandarin words could be flagged as such regional, dialectal, etc, e.g. I - 俺 (ǎn) (regional), how - 咋 (zǎ) (regional), etc. I don't see the need for them in translations but in separate entries. Anatoli 13:11, 10 May 2009 (UTC)
- 1 - this is the ſtraightforward approach, I already expreſt mine opinion, vide ſupra. The uſer hight Bogorm converſation 13:19, 10 May 2009 (UTC)
- By "status quo," I'm referring to the format that can be found in the translation section for carnation and child. -- A-cai 15:06, 10 May 2009 (UTC)
- That's 1 then. The child has 3 levels. Is it really necessary? Can we keep to 2 levels? For example, ** Min Nan: 囡仔 (gín-á), 孥囝 (nou5gian2) (Teochew)? Anatoli 22:39, 10 May 2009 (UTC)
- 1 - like carnation.--Ccsheng125 04:51, 13 May 2009 (UTC)
- 2, or 1. On the actual stated difference between 1 and 2, I think that 2 is better, but that 1 is still O.K. The issue I consider more important is the one labeled "However, this can be decided later": whether to give Mandarin preferential claim over the name "Chinese", or whether to say that all these languages are equally "Chinese" and equally not. If we indent them all under "Chinese", then that should go for Mandarin as well; and if we list them all out separately, then Mandarin should be labeled "Mandarin", not "Chinese". (That said, if we don't group the languages, I would accept something like "Mandarin Chinese" to help people who are searching for "Chinese" to find the Mandarin translation, since that's probably what they want.) —RuakhTALK 16:30, 10 May 2009 (UTC)
- 1 for me, because that is how we think of this group and how we look it up. —Stephen 15:49, 11 May 2009 (UTC)
- If the decision is to split Chinese languages/dialects (I am not in favour of this), "Chinese Mandarin" is better (or even Chinese (Mandarin)) than "Mandarin Chinese" because people look for Chinese dictionaries, not Mandarin. For example, Google translates into Chinese, not Mandarin.
- This is not to neglect Chinese dialects and I am not playing any political games. It is for users wanting to know how to write/say something in Chinese, in 99% of cases they want to know the standard or Mandarin translations, when they want the Chinese translations. I know that terms Chinese and Mandarin are not identical terms but they are for many users in practice.
Anatoli 22:39, 10 May 2009 (UTC)
- 1. Ƿidsiþ 10:56, 13 May 2009 (UTC)
- Whoa this is gettung waaaaaaaay too long. Partially a case of on my part. Anyway in my opinion the nesting is best so put me down for that. 50 Xylophone Players talk 17:02, 19 May 2009 (UTC)
- 1. I think that most people would find it most natural to look for Chinese when they want to know what an English word are called in Chinese. Notice that both google's translation tool and babel fish use the world Chinese not Mandarin. Kinamand 11:25, 2 June 2009 (UTC)
- So, 1 won decisevely and we may finally start grouping the dialects under Chinese in the translations. What about a Chinese header for entries as well? The uſer hight Bogorm converſation 18:08, 4 August 2009 (UTC)
For those who have an interest in the logo vote, now is your chance to decide how nominations should proceed. Conrad.Irwin 19:46, 5 May 2009 (UTC)
- I've had a new idea for a logo and made a quick mockup. See the favicon topic. — hippietrail 03:47, 12 June 2009 (UTC)
- Submit it on the proposals page, not here... Conrad.Irwin 15:29, 12 June 2009 (UTC)
Needed: Wiktionary:About Croatian and Wiktionary:About Lithuanian
I would like to ask the main contributors of Croatian and Lithuanian info to the English Wiktionary to make some "about" pages like we have for several other languages.
In particular I have noticed that some editors have been adding pronunciation diacritics in the "alt" version of words in these two languages and I would like it documented somewhere exactly which diacritics are used for each language and what they indicate. For an idea of what else to include in such pages please see the existing ones in this category: Category:Wiktionary language considerations — hippietrail 05:50, 6 May 2009 (UTC)
- There is no need for Wiktionary:About Croatian - Ivan, who is a Croatian user, already created Wiktionary:About Serbo-Croatian, all you need is there. See the discussion for that at Wiktionary:Beer_parlour/2009/March#Serbo-Croatian (already archived) or on the talk page there where the approach is justified. The uſer hight Bogorm converſation 06:27, 6 May 2009 (UTC)
- Then I shall make a redirect. Thanks. — hippietrail 11:42, 6 May 2009 (UTC)
- Call me out by name, why doncha! =p I'll see what I can do about WT:ALT — [ R·I·C ] opiaterein — 22:54, 7 May 2009 (UTC)
The new look of the translations tables
I haven't been very active since the new look of {{trans-top}} has been effected. I'm not going to assert it's because of that change, but the new look certainly puts me off, seriously. I think it's awful and it gives me associations of being a software programmer or something way too technical for my comfort. I would expect other users to be alienated by it similarly. I have looked around (including the template talk page) for others who had brought this grievance to the fore, but I haven't been able to spot any discussion threads on this topic. Are there some that I haven't noticed? Or am I merely a lone discontented voice out-of-synch with the public opinion on this? __meco 08:44, 6 May 2009 (UTC)
- Ya it's pretty clumsy and confusing looking. Off-putting. -- Thisis0 15:27, 6 May 2009 (UTC)
- I much prefer the new look. The old boxes were impossible to get rid of if you didn't care to see them. Now that they're collapsible, it's much easier to work around them. The only thing I can think of that I would change is the background color. That pale yellow is a little bit icky. — [ R·I·C ] opiaterein — 23:01, 7 May 2009 (UTC)
- Ah, that is not the new change, that's the "old change" – which I'm all for. It's the added options and ability to move entries between columns which I find so confusing and annoying. __meco 01:14, 8 May 2009 (UTC)
- If I understand correctly what you are referring to, it's called Assisted Editing, and was coded by Conrad Irwin. See the discussions above entitled "Editing without Wikitext? Introducing User:Conrad.Irwin/editor.js" and "Assisted editing a success?" to read the discussion about it. Hope this helps! 75.215.191.18 (really, User:JesseW/not logged in) 07:22, 8 May 2009 (UTC)
- You can turn off the new buttons at WT:EDIT, though if you have an idea for making that interface look more friendly I'd be very glad to hear it. Conrad.Irwin 08:05, 8 May 2009 (UTC)
- I wonder if it could be hidden until the user clicks on "Add". (This would allow adding to every translation table on the page?) Also there was the suggestion to spread the interface across the bottom using both columns so that every table doesn't look unbalanced. DAVilla 04:34, 10 May 2009 (UTC)
Special Characters in edit box like Wikipedia
Hey, I would assume this has been asked before, but I can't find the thread. Why-come we don't have a special characters box present on the 'edit' page, to insert special characters? You have no idea how many times I click over and find a random wikipedia page and click 'edit' just to nab some curly quotes or a dash. -- Thisis0 15:26, 6 May 2009 (UTC)
- We do. it's just under the Save page button. (If you click on the drop-down menu, you will see even more possible sets of characters/templates than even Wikipedia use). Conrad.Irwin 15:28, 6 May 2009 (UTC)
Script userboxes see below @ WT:BP#User script templates
If no one objects, I'd like to start making things like w:Template:User cyrl-2 and w:Template:User ipa-3 soon, to show knowledge of various scripts, to go with our knowledge-of-various-language userboxes. I've brought up something similar to this before, but I kinda forgot about it. Anyway, I'd like to start doing this by the end of next week at the latest — [ R·I·C ] opiaterein — 22:59, 7 May 2009 (UTC)
Template:en-adj provides false information by default
Default use of {{en-adj}} (with no parameters) displays "more"/"most" as comparative and superlative forms of an adjective, which is incorrect for most common English adjectives. If someone writes an entry on English adjective and is not aware what {{en-adj}} actually does (one may think it just adds an entry to a proper category) and does not look carefully on the preview, they may save false information.
Most recent example: edit in "phoney" by a native English speaker. I think that as not all editors of English Wiktionary and definitely not all readers of it are native users of English language, many of them may not spot the mistake in entries.
I think that no template, and especially this, should generate any automatical, default inflection forms. --Derbeth talk 10:53, 9 May 2009 (UTC)
- Well, actually, most of these (deprecated template usage) more + [adj.] and (deprecated template usage) most + [adj.] constructions do occur, and in the case of the more common adjectives, virtually all of them can be attested in such comparative and superlative constructions. Take, for example, your example: “more phoney” is pretty common, whilst “most phoney” is also pretty clearly attestable; OTOH, phonier and phoniest are more common (whereas phoneyer and phoneyest are much rarer). Whether such constructions are standard or not is very much up for debate; however, since we ostensibly wish to include “all words in all languages”, it is appropriate for
{{en-adj}}to display these comparative and superlative constructions automatically since, in the vast majority of cases, it will be reflecting the facts by doing so. † ﴾(u):Raifʻhār (t):Doremítzwr﴿ 11:29, 9 May 2009 (UTC)
- It's a little hard to check this on the corpus of Current American English because [most + Adj] will find both relevant constructions like the most important thing we can do, where most modified important, and irrelevant constructions like most young people enjoy pop music, where most determines people. Still, with that proviso in mind, I poked around and it looks like there are thousands of legitimate most + Adj combinations, where there are fewer than 1,000 adjectives that take the morphological ending -est.--Brett 15:20, 9 May 2009 (UTC)
- It’s also worth noting that almost all monosyllabic words can form their comparative and superlative forms by the suffixation of -er and -est, respectively, as can very many disyllabic words; however, very few tri-or-more-syllabic words can do this, their forms being constructed phrasally as (deprecated template usage) more + [adj.] and (deprecated template usage) most + [adj.]. † ﴾(u):Raifʻhār (t):Doremítzwr﴿ 15:26, 9 May 2009 (UTC)
- I rather doubt that the community would ever accept your viewpoint that "no template […] should generate any automatical, default inflection forms" since we use just that feature to generate English plurals, as well as most forms in most declension tables throughout Wiktionary. It would be extremely time-consuming to have to enter the 100+ inflectional forms of Latin verbs by hand, rather than using the current templates (which require the user to enter at most 6 parameters). I fail to see how asking users to enter those 100+ forms by hand would reduce the numbmer of errors generated. I expect quite the opposite would happen; we would have more errors and they would be harder to spot. --EncycloPetey 21:19, 9 May 2009 (UTC)
I think it's better to have no information in 100,000 entries than have false information in say, 1,000 entries. Like on Commons: better to remove all files with missing copyright information than risk that one per 1,000 or 10,000 of these files would cause a legal action against the service. Providing false information causes service reputation to be seriously damaged, it's not easy to rebuild it later.
If Wiktionary is to follow the rule of "no original research" and verifyability, it should not take Google as a reliable source, because there are lots of people who don't know how to speak or write in their own language. --Derbeth talk 18:09, 9 May 2009 (UTC)
- I bed to differ with utmost emphasis. I they "didn't know how to speak or write", then they wouldn't write to begin with, and we couldn't understand the language. I just don't like it is valid on Wiktionary too. More people are writing, and more of that writing is accessible now than ever before. It's patent to anybody with a modicum of logic that there will also be more documented language variation (compare the similar variations when Old English began to be written, and in the 18-19th when more people began writing, these were times of massive language creativity). Circeus 19:30, 9 May 2009 (UTC)
- Wiktionary cannot, and does not use "NOR", it does use WT:CFI which does prevent use of anything that is not "durably archived" (i.e. most of the internet). If you think that words don't meed CFI, then they should be deleted or RFV'd, if you think CFI is wrong, then that is another matter - but I doubt it will be changed much. Many of our inflection templates automatically cater for the most common types of word - this is desirable, as it saves effort on behalf of contributors. As with everything, mistakes will be made (more so by newcomers), but these are (from experience) no more common than the mistakes that are routinely made throughout entries. Conrad.Irwin 19:47, 9 May 2009 (UTC)
- A good bulk of the entries that use -er and -est have already been created because these are, generally speaking, the shorter words. For the rare exceptions, a contributor will be very likely to catch the mistake even if unfamiliar with Wiktionary when he or she reviews the page. Plus, virtually all new entries by anons and new users are looked over by admins (SB in particular) to check for vandalism. There are bigger worries for correctness of content. DAVilla 04:25, 10 May 2009 (UTC)
- It is unthinkable to expect less than 1% error rate in a wiki. Also, errors of fact on one hand and copyright violations on the other hand are two groups of issues with varying risk and seriousness levels. And, Wiktionary is a descriptive dictionary, documenting above all how people actually use the language in durably archived media, not how someone thinks people should be using the language. Google is not being used as a source; Google is used to find sources that use the terms to be documented, such sources as printed books available in Google books. --Dan Polansky 08:15, 10 May 2009 (UTC)
I think that making a template provide false information in more than marginal number of cases by default is completely crazy. It's like introducing mistakes in random places all over the project. Yet another recent example I found: uncountable noun shown as countable. If person creating the entry decided (perhaps just because they forgot it) not to fill the word inflection, the entry should have no inflection. Not some "default" one.
You cannot treat all adjectives as using "more"/"most" for building comparative and superlative and you cannot treat all nouns as being countable. The other option is perhaps as popular as the previous. Lots of words describing abstract ideas are uncountable.
I cannot image how anybody could trust a dictionary providing random information. This is like Wikipedia provided a default value for city population in its infoboxes. Fortunately it does not. --Derbeth talk 09:51, 10 May 2009 (UTC)
- For the template to generate an incorrect result, it would have to be used by someone who knew of the existence of the template, but not of the documentation (which would imply a newcomer), and not have had their edit checked, and most newbie edits are patrolled (particularly page creation). [Alternatively it could just be a mistake by anyone, but mistakes happen everywhere all the time]. While I will happily admit that there are problems with the templates that we use, doing the right thing by default is not one of them. Conrad.Irwin 10:17, 10 May 2009 (UTC)
- This seems to belong to the broad topic of defaults in templates. Given you are a software developer, think of a method in C++ that provides a default parameter. It is up to the caller of the method (or template) to make sure the default behavior fits the case to which the method is applied; if it does not fit, the parameter should be explicitly provided by the caller. While Java does not support defaults directly in the way in which C++ does, it can do a similar thing by having several methods of the same name but varying number of parameters. This is routinely done in Swing. Errors in method calling are by no means constrained to the misuse of default parameters.
- It is not the dictionary or the template that provides "random information"; it is the person who entered the template without explicit parameters who entered an error. By your reasoning, there should be no defaults for templates at all (defaults that make a difference in facts rather than formatting), because there is always a chance that the editor forgets to enter a parameter when entering the template. But then, there is also the chance that the editor enters a wrong template. And there is also the chance, one for which wikis are criticized, that editors who do not know what they are doing enter false information. As I see it, the burden for using templates correctly is with the person who enters the template. There is the broad wiki principle that wikis are almost by definition revisionist, Popperian, so to speak, not only getting cumulatively extended, but also getting corrected. Entering wrong information without templates is an order-of-magnitude more ample source of wrong information than a template that is not fool-proof.
- On the benefits side, defaults in templates make it clear that there is a regularity to which there are exceptions, even if numerous exceptions.
- To go for a specific another example of template, there is the, AFAICT, very useful automatic declension template
{{cs-decl-noun-auto}}, which requires the user of the template to verify that the results are correct. Still, that makes it possible to see clearly whether the declension of the word is perfectly regular or whether there is an exception. The template saves a considerable amount of work, but produces wrong results when entered mindlessly. - Not all parameters of templates (and methods) are amenable to defaults. It is when a parameter gets the same value for a large number of calling cases that a default is in order. There is no repetation of sizes of populace of cities, so there is no supported default. Because the majority of English adjectives do get graded using "more ..." and "most ...", a default makes sense. On the other hand, if there would be no exception to the rule, there would be no parameter at all, as there would be nothing to distinguish. --Dan Polansky 11:25, 10 May 2009 (UTC)
- Derbeth, is this a purely hypothetical situation, or did you find a significant number of erroneous entries? Which ones? Did you correct them? --EncycloPetey 19:59, 10 May 2009 (UTC)
So I got right on the ball with this one for once, and now you can use these templates in your Babels the same way you use the language templates. Hope this catches on well :) — [ R·I·C ] opiaterein — 23:22, 9 May 2009 (UTC)
- Forgot to mention, in case anyone feels like knowing before jumping into the category, we currently have 13 scripts fully covered from level 0 (no knowledge) to N (native user) Arabic (code Arab), Armenian (Armn), Bengali (Beng), Cyrillic (Cyrl), Devanagari (Deva), Georgian (Geor), Greek (Grek), Hanzi (Hani, Hant and Hans), Hebrew (Hebr), Latin (Latn) and Thai (Thai) — [ R·I·C ] opiaterein — 23:26, 9 May 2009 (UTC).
Attestability for transcriptions
Should not words such as hoeng1gong2 jyu5jin4hok6 hok6wui6 jyut6jyu5 ping3jam1 fong1on3 be attested (use, not mention), or is there a special rule for transcriptions? I would think that a single attestation might be sufficient in such cases, but that at least one should be required. I cannot find the answer in policy pages. See Talk:hoeng1gong2 jyu5jin4hok6 hok6wui6 jyut6jyu5 ping3jam1 fong1on3. Lmaltier 17:06, 10 May 2009 (UTC)
- I don’t see why they should be attested, but I also don’t believe we should have entries for most transcriptions. Mandarin written in Pinyin is one of the few exceptions, since some publications actually write Mandarin this way. Entries for Hepburn transcriptions of Japanese are okay, since they are so standard and we often see Japanese written that way. But delete hoeng1gong2 jyu5jin4hok6 hok6wui6 jyut6jyu5 ping3jam1 fong1on3 and confine the transcription to 香港語言學學會粵語拼音方案. —Stephen 15:56, 11 May 2009 (UTC)
- This was my concern. I agree. Lmaltier 19:27, 11 May 2009 (UTC)
xx-inflection of
I want to create a couple of language specific inflection "offspring" of {{inflection of}} starting with {{is-inflection of}} which should support inclusion of {{strong}}, {{weak}} and {{posi}}. Can someone do this for me so that I might be able to manage the creation of any other that may need to be created? 50 Xylophone Players talk 19:13, 10 May 2009 (UTC)
P.S. Explain everthing in plain English as I know next to nothing about programming languages, etc.
- Note: The template already supports those, it just doesn't do so with abbreviated forms. The template was set up to allow abbreviated forms for a few of the more common grammatical items, but when something is included that isn't part of the abbreviated set, it displays whatever was entered.
- It should be a simple matter to set up
{{is-inflection of}}. I can do that, if you like. But, as I said, the current template will already accept and display strong, weak, etc. if you include those words as unabbreviated parameter values. --EncycloPetey 19:57, 10 May 2009 (UTC)- Oh, really? Well, I don't know enough about this stuff to have been able to realise that. I think I'll make
{{stro}}as a redirect (I'm just thinking for the sake of speedy creation) I seem to remember being unable to type indef and get the desired result with inflection of before. Can you explain to me why this occurred? 50 Xylophone Players talk 20:12, 10 May 2009 (UTC)
- Oh, really? Well, I don't know enough about this stuff to have been able to realise that. I think I'll make
- If you want to add additional shortcuts, then you should have a separate template. Because of the template coding, only the most common and widely used options were included. Adding more options increases strain on the server. There is also little reason to abbreviate "strong" to four letters. If you use "indefinite", it will support that. If you see a need for a separate template with its own shortcut "indef", then that is also a possibility. However, the current setup does not suppport the abbreviation "indef". Each additional abbreviation increases the server strain from the template for all entries using the template. --EncycloPetey 20:14, 10 May 2009 (UTC)
- So how does
{{hu-inflection of}}accept ine, tran, efor, cfin, etc? 50 Xylophone Players talk 20:21, 10 May 2009 (UTC)- It calls another template
{{hu-grammar tag}}that has been given a list of acceptable abbreviations for use with the template. Open the source for that secondary template to see the list. Even with no programming experience, the list in the coding should make sense.
- It calls another template
- So how does
- If you want to add additional shortcuts, then you should have a separate template. Because of the template coding, only the most common and widely used options were included. Adding more options increases strain on the server. There is also little reason to abbreviate "strong" to four letters. If you use "indefinite", it will support that. If you see a need for a separate template with its own shortcut "indef", then that is also a possibility. However, the current setup does not suppport the abbreviation "indef". Each additional abbreviation increases the server strain from the template for all entries using the template. --EncycloPetey 20:14, 10 May 2009 (UTC)
- The way the two templates function is: The primary template accepts the data and formats the text for the definition line. The primary template asks the secondary template for help with the grammar abbreviations (any parameters in position 2 or 3, in this Hungarian instance). The secondary template then contains a list of acceptable abbreviations, checks against that list, and expands it to the full form when one is used. --EncycloPetey 23:05, 10 May 2009 (UTC)
- Ahh, so what I need is
{{is-grammar tag}}? 50 Xylophone Players talk 23:15, 10 May 2009 (UTC)
- Ahh, so what I need is
- The way the two templates function is: The primary template accepts the data and formats the text for the definition line. The primary template asks the secondary template for help with the grammar abbreviations (any parameters in position 2 or 3, in this Hungarian instance). The secondary template then contains a list of acceptable abbreviations, checks against that list, and expands it to the full form when one is used. --EncycloPetey 23:05, 10 May 2009 (UTC)
- Yes. Note that the method used for the Hungarian templates differs from the way the generic
{{inflection of}}template works. It is able to do so by (1) limiting the number of calls to the secondary template to just two, and (2) having a language-specific list of abbreviations. By contrast, the generic template allows for a variable number of grammatical parameteters, but is limited to a small set of abbreviated forms. Anything it doesn't recognize as an abbreviation is presented as it was entered. --EncycloPetey 23:05, 10 May 2009 (UTC)
- Yes. Note that the method used for the Hungarian templates differs from the way the generic
Webster's quoteless quotes
Many word senses imported from Webster's 1913 dictionary end with an author's surname, but without a proper quote (e.g. upflow). Obviously a real quote would be preferable, but is there a better way we can format this? Single word surnames should obviously be expanded to full names so that when "Speed" is mentioned after sense #2 of abider one doesn't confuse w:John Speed and speed. Anything more than this? --Bequw → ¢ • τ 09:32, 12 May 2009 (UTC)
[This version of abider] is the one that illustrates Bequw's point. DCDuring TALK 11:49, 12 May 2009 (UTC)
- I wonder whether some adept could devise or suggest one or more tools to speed the location and insertion of the proper quote. The idea would be to automagically insert the author's name and the quote (or headword) into a google search template and then speed the manually selected quote into
{{quote-book}}. DCDuring TALK 10:58, 12 May 2009 (UTC)
- It is possible to speed the quote-finding process by wrapping
{{b.g.c.}}around the quote, previewing, and getting the material from the search results. Often a WP link to the author is needed for the original year= date. I don't know whether further speeding is possible, but I haven't been inserting urls because of the extra keystrokes required. DCDuring TALK 11:49, 12 May 2009 (UTC)
Reverts at Wiktionary:Criteria for inclusion.
See Wiktionary:Criteria for inclusion?action=history.
The banner at the top of the page clearly states that it "should not be modified without a VOTE." Further, we recently had a VOTE to change that to "should not be modified without discussion and consensus. Any substantial or contested changes require a VOTE", and said VOTE failed. However, editors continue to make modifications — without even discussion, as far as I can see.
So the de facto policy seems to be merely that "Any substantial or contested changes require a VOTE"?
—RuakhTALK 13:36, 12 May 2009 (UTC)
- I think it's more like "Any policy changes require a VOTE", which leaves out typos and the like (imagine if we did a VOTE to correct every typo) -- Prince Kassad 13:41, 12 May 2009 (UTC)
- Re: "imagine if we did a VOTE to correct every typo": Yes, that's why most people voted not to require a VOTE for unsubstantial and uncontested changes — but that failed, so we do. (In the case of a typo, I think a note at the talk-page, and waiting a day or two for comments (to make sure that it is in fact a typo), should suffice for the "discussion and consensus" clause.) —RuakhTALK 13:57, 12 May 2009 (UTC)
FYI, the referenced vote is Wiktionary:Votes/pl-2009-03/Removing vote requirements for policy changes. 16 people said it should be OK to make minor changes like this one, but 7 people opposed the idea, so the voting requirement stands. :-( —Rod (A. Smith) 15:22, 12 May 2009 (UTC)
- We would probably need to have a dreaded Vote to amend WT:CFI. For example, we need to:
- incorporate no-change-without-a-vote language,
- correct those portions that are drafted so as to allow internal contradictions to develop
- remove elements that might be better on a more flexible policy page (not as tightly protected as this) or a guidelines page.
- You could think of WT:CFI as a part of a wiktionary "constitution", intentionally inflexible. But perhaps we haven't finished drafting it yet. DCDuring TALK 15:44, 12 May 2009 (UTC)
- The irony of it is that no one ever approved the CFI; as far as I can tell, it magically become immutable when a certain editor replaced the old version of
{{Policy-SO}}("This Policy has Semi-Official status, having some degree of support in the community. Please see the discussions on the attached Talk: page if you want to contribute to the further development or adoption of this policy, to bring it to the level of Wiktionary Official.") with a redirect to{{policy}}(which he had just changed to read "Wiktionary Policies, Guidelines and common practices page. It should not be modified without a VOTE."). Before 28 January 2007, we did have a fully-functional VOTE process, but for some reason the aforementioned editor bypassed that process when he instituted CFI (and all other policy think-tanks and semi-official policies) as policy that could only be mutated by that process. (Note: I'm not naming the editor in question, because I don't know whether he was acting unilaterally, and it doesn't seem that anyone really objected. But if you want to ask him about it, look in the history of any of the policy templates.) —RuakhTALK 16:03, 12 May 2009 (UTC)
- The irony of it is that no one ever approved the CFI; as far as I can tell, it magically become immutable when a certain editor replaced the old version of
- Right. CFI became official with this change. The only related comment I can now find is the one currently at the top of Template talk:policy, but I think it was part of a policy struggle between that editor and Gerard (who subsequently left Wiktionary to start the project now known as OmegaWiki). —Rod (A. Smith) 16:50, 12 May 2009 (UTC)
- DAVilla, Ruakh and Rod are right. If more people than those who actually voted wish to change the metapolicy that currently reads "It should not be modified without a VOTE", let them state it here and the vote can be restarted.
- On another note, there is a thing about the metapolicy that I, a non-native, find slightly confusing. It says "should not", not "must not". In Czech, "should not" would be read as "in most cases better to avoided, but people will do it anyway", but I vaguely remember that, in English, "should not" is used as a polite way of saying "shall not" or "must not". Then, is "should not" actually meant as "shall not" and "must not", that is, "under no conditions and circumstances is it allowed under the pain of penalty of blocking" or something of the sort? (Excuse the non-native confusion, please.) Do we have a guide here on Wiktionary on these deontic (duty-like or obligation-like) modalities? --Dan Polansky 16:04, 12 May 2009 (UTC)
- Your understanding is right. "Should not" is very strange here, since it doesn't imply that it's absolutely forbidden (as, say, "must not" would), but does imply that there are no exceptions (unlike, say, "generally shouldn't"). "Should not" makes sense in circumstances where there's no enforcement (e.g., "You shouldn't expect him to come", where it's entirely up to you whether you actually do expect him to come), but it doesn't make much sense here. (Re: "I vaguely remember that, in English, 'should not' is used as a polite way of saying 'shall not' or 'must not'": that's true, but it's a very bureaucratic thing, used when an institution has a great deal of control. In normal circumstances, the polite way to say it would be something like, "Please do not modify this page, except to implement the results of a VOTE.") —RuakhTALK 17:01, 12 May 2009 (UTC)
Does anyone else find this perversely hilarious? —Michael Z. 2009-05-12 16:16 z
- Hell, yes. † ﴾(u):Raifʻhār (t):Doremítzwr﴿ 16:42, 12 May 2009 (UTC)
- It seems like an organic, common-law-style, wiki-like development of a constitution, more visible if not more risible than the typical law- or sausage-making process. DCDuring TALK 16:52, 12 May 2009 (UTC)
- Notwithstanding its origins. DCDuring TALK 17:05, 12 May 2009 (UTC)
- It seems like an organic, common-law-style, wiki-like development of a constitution, more visible if not more risible than the typical law- or sausage-making process. DCDuring TALK 16:52, 12 May 2009 (UTC)
- I would, if I didn't find it so frustrating. The CFI are seriously broken, and there's no consensus for them — but somehow they're policy, and we can't fix them without consensus? Even if the latest VOTE had passed, I'd find this frustrating; but its failure is beyond. —RuakhTALK 17:01, 12 May 2009 (UTC)
- The recently failed vote and the nature of the trivial factual edit which prompted this[1] emphasizes that both parties are in the right. Our guideline has not only utterly failed, but thwarts resolution. Please, let's rerun the other vote immediately instead of wasting time voting to make the change to CFI. —Michael Z. 2009-05-12 18:25 z
- Reverting improvements is petty.
- Any improvement made is an improvement. Reverting it because of some ridiculous notion of "incorrect process" is beyond petty - it's a harmful waste of everybody's time.
- Out of date policy pages are useless.
- Our policy pages don't match our policy/"universal accepted norms". This needs fixing, by whom and using what "process" I really don't think it matters.
- The VOTE about policy pages was flawed.
- The issue is that the supporters were in favour of changing "policy pages", and the opposers were against changing "policy". These are not the same.
Conrad.Irwin 18:38, 12 May 2009 (UTC)
- The issue is not "incorrect process", but rather "violation of policy". And an improvement is not an improvement if it establishes the precedent that policy is not policy. Without some sort of consensus (1) that the edit was O.K. and (2) on exactly why it was O.K., it simply creates problems. And if we have that consensus, then we should have no difficulty passing a VOTE to fix
{{Policy-SO}}accordingly. - If you believe the VOTE was flawed, then please, for Pete's sake, start an non-flawed one!
- I wonder what would happen if we had a VOTE to accept CFI as policy?
- —RuakhTALK 20:06, 12 May 2009 (UTC)
- The issue is not "incorrect process", but rather "violation of policy". And an improvement is not an improvement if it establishes the precedent that policy is not policy. Without some sort of consensus (1) that the edit was O.K. and (2) on exactly why it was O.K., it simply creates problems. And if we have that consensus, then we should have no difficulty passing a VOTE to fix
- In no way were the improvements that have been made thus far a violation of policy, taking a purely legalistic view. Firstly, the text "It should not be modified without a VOTE" was added with no VOTE, and has thus no "policy" status. Secondly the vote that failed was "Removing vote requirements for policy changes" NOT "Removing vote requirements for policy page changes". People have always tweaked these pages to improve spelling and other similar mistakes without the need for a VOTE, the fact that a vote for the negation of something similar failed does not mean that a VOTE for "No one may edit a policy page without a VOTE" would succeed, and given that it failed with the majority supporting it, I find it incredibly hard to believe that the opposing point of view has demonstrable support either.
- I have started a further discussion below, that may lead to a VOTE.
- Voting on CFI is something we should do, but it will need a few hours of work before the page reflects the policy accurately enough to be voted upon. Conrad.Irwin 00:54, 13 May 2009 (UTC)
I wonder: why are WT:CFI and WT:ELE not protected so that only admins can edit it, just like {{policy}}? That would reduce unwanted reverting interchanges to those among the wheels. This would make it less critical to protect the page by soft "should-not-be-modified" meta-policies. Edits like this from 2 March 2009 would be impossible. Afterwards, relaxing the "should-not-edit" metapolicy should be less critical. --Dan Polansky 21:16, 12 May 2009 (UTC)
- Doing so would bring false benefit, as admins are just as capable of making a mess of them as anyone else. Conrad.Irwin 00:54, 13 May 2009 (UTC)
- Although that is inconsistent, you are finding flaw with the wrong policy, in my view. Admins are trusted parties, but we are not the gatekeepers of what does and does not pass here, apart from what the community as a whole has decided, which is always open to interpretation in the first place. For instance, redirects have always been strongly opposed, but there are exceptions made even by those who oppose them. My views on how Chinese should be listed in translations are no more correct than those of a new contributor. Wiktionary documents all words in all languages, as is said time and again, but it turns out constructed languages needed further deliberation. Setting policy in stone is entirely anti-wiki. DAVilla 05:20, 13 May 2009 (UTC)
- I think there is a series of increasing levels of trustworthiness, from (a) anons, (b) registered users, and (c) admins. None of the groups is infallible, but there are clear differences. While many registered users are inexperienced and many take part in vandalism before they get blocked, this cannot be said of an admin, who first needs to gain a great majority - 75% support of the community in a formal vote to become one.
- Only time would should what kind of further disputes admins would create about WT:CFI if WT:CFI is locked and the soft rules for its modification are relaxed.
- Locking WT:CFI, as has now been done, only makes the soft metapolicy technically effective: given WT:CFI should not be modified without a vote, there is no point in the page being editable by any registered user. If WT:CFI is unlocked again, this will mean that Wiktionary:Votes/pl-2009-03/Removing vote requirements for policy changes is not taken all that seriously as failed. Now I am not saying that the vote should be considered failed; I do not know, and I think the only thing worse than an unfair domination of a minority by a majority is an unfair domination of a majority by a minority, hence the imperfect but practical majority (50%) rule used in democracies. --Dan Polansky 09:09, 13 May 2009 (UTC)
- I'm not so sure we should consider that vote as having failed, but even if we have to put it through again it will eventually pass in some form, at which point the basis for a lock will have to be reconsidered. DAVilla 17:44, 13 May 2009 (UTC)
Update. I've un-failed the aforementioned vote ([[q.v.). —RuakhTALK 19:53, 13 May 2009 (UTC)
Moving on
I feel that we must be very careful that we never need to introduce an Ignore all rules "policy" which, I assume, became necessary on Wikipedia because the policy lawyers were making bad rules. As I see it, at the moment our two main policy pages (and many of the others) are flawed because they try and interweave too much of what is "policy" with explanations and descriptions of "common practice". I propose changing this so that WT:ELE and WT:CFI contain documentation on the "current practice", leaving the pages Wiktionary:Layout policy, and Wiktionary:Inclusion policy containing short paragraphs codifying actual explicitly worded and voted on "policy". Yes, common practice will never contradict policy, and new policy can (and should) be derived from common practice. Then we could usefully have a rule that "policy cannot be modified without a VOTE", while leaving WT:ELE and WT:CFI under a looser restriction such as "An incorrect change to this page may result in a block." While this might seem an extreme solution, it is clear to me that we need to do something to prevent there being any "policy" that can ever be violated for a justifiable reason. Conrad.Irwin 00:54, 13 May 2009 (UTC)
- Strong support. —RuakhTALK 01:02, 13 May 2009 (UTC)
- That's the cleverest idea. Do it, and please unprotect the page. Admins are users who may still skim but not longer scrub the policy pages, and cannot be solely trusted to polish them. DAVilla
- Sounds good. However, "Yes, common practice will never contradict policy, and new policy can (and should) be derived from common practice" looks like a statement of a deadlock. A change needs to happen somewhere first: either in the practice or in the policy. If a policy is meant to always fall behind practice (as it is derived from it), then a policy cannot be considered unconditionally obligatory. The very term "policy" seems odd to apply to a document that only documents current practice after the fact. --Dan Polansky 08:42, 13 May 2009 (UTC)
Just a minor comment. But having a vote to change the numbers in CFI to reflect how many ISO codes there are is completely ridiculous. You want to vote on keeping Wiktionary up to date? You want to vote on such a stupidly minor issue? I can't believe this made it to BP and how silly you all can be sometimes :P Shit like this is the reason I don't edit Wikipedia anymore. But then, I doubt even they would treat this issue as it's being treated here and now. — [ R·I·C ] opiaterein — 01:56, 13 May 2009 (UTC)
- Re: "You want to vote on such a stupidly minor issue?": Don't worry, I don't think anyone wants that. At least, I really hope no one does; and I'll be amazed (in a bad way) if this actually ends up coming to a vote on that. The question is, how do we avoid such stupidly minor votes? —RuakhTALK 02:17, 13 May 2009 (UTC)
- Support. What Conrad said seems great. DCDuring TALK 03:22, 13 May 2009 (UTC)
- Yes. The challenge will be figuring out what needs to be moved over to policy before switching ELE and CFI to descriptions of common practice. Hopefully RU and msh and the others who supported hard-to-change policies will speak up about what parts of ELE and CFI they consider critical. JesseW 05:42, 13 May 2009 (UTC)
- I've no time at the moment, I'm afraid. But surely those who voted for easier-to-change policies also have views on that question.—msh210℠ 17:06, 13 May 2009 (UTC)
- Yes. The challenge will be figuring out what needs to be moved over to policy before switching ELE and CFI to descriptions of common practice. Hopefully RU and msh and the others who supported hard-to-change policies will speak up about what parts of ELE and CFI they consider critical. JesseW 05:42, 13 May 2009 (UTC)
- I support CI's proposal.—msh210℠ 17:06, 13 May 2009 (UTC)
An analogy with constitution has been invoked, to justify the requirement of 75% majority. Isn't it that a constitution first needs to be accepted by such a great majority in order to become effective? Under this line of thought, the statement "the policy should not be modified without a vote" has never acquired the status of constitutional statement. Put differently, in order for a change of a statement to require a great majority (75%), the statement first must have been enacted by a great majority (75%). Thus, the statement "the policy should not be modified without a vote", which looks like constitutional for its being a meta statement about policies, is not constitutional for its never having been voted on, and thus, formally speaking, is invalid, not formally enacted. --Dan Polansky 09:09, 13 May 2009 (UTC)
- It need not be done exactly like that. The Magna Carta was never voted on by the "people", nor was it signed, but was considered to enact many of the rights of English commoners. It was itself largely based on the w:Charter of Liberties, an earlier statement of limits on the powers of the Crown voluntarily decreed by a Henry I.
- We would look to WMF for hard and fast procedure. Otherwise, it is our own desires and expectations that shape things. My only thoughts were that our rules about voting itself were worthy of some kind of strong "constitutional" protection. Otherwise, there just needs to be some core of policy which requires votes to change. Whatever we invoke to justify summary deletion of contributions and blocking of users (as we now invoke WT:CFI) should be policy. (Not to say that enforcement won't require interpretation and discretion.)
- There should be plenty of opportunity for guidelines and draft and proposed policies and guidelines that codify our best practice and thought for accessibility. I would argue that no uncodified practice should have any force whatsoever, so as to compel more codification so would-be contributors have something to learn from. Lists of leading examples of good entries would be a perfectly good alternative approach. DCDuring TALK 18:16, 13 May 2009 (UTC)
- Support with modification. I agree very much that we need to separate the policy from the "how-to" in our two primary documents. However, I prefer keeping ELE and CFI as the policy pages, since that is what they have been in the past (and what they are in past discussion threads). Rather than convert them to practices pages, with policy split out into new pages, I advocate distilling down the policies in those pages while relocating practices descriptions to new locations. --EncycloPetey 01:42, 21 May 2009 (UTC)
are we biting the newcomers?
I hate to criticize Wiktionary's fine administrators, but there is something that has been bothering me for some time. It seems many users are blocked for making just a single test edit or two. For example, 216.120.137.66 (talk) made a test edit to compensate, which I had reverted. There was no further vandalism from 216.120.137.66 after I warned them, but they were still blocked. Granted, I am not an administrator and have no access to Special:DeletedContributions, so I cannot tell if any of those users were blocked for creating inappropriate pages. However, I feel that these blocks go against Wiktionary:Assume good faith.
In comparison, Wikipedia users who make disruptive edits are often warned several times before they are blocked. On Wiktionary, many blocked users were not even warned once. I know Wiktionary isn't Wikipedia, but I feel that many of the blocks are a bit on the harsh side. Wiktionary's blocking policy clearly states that "simple 'Dave is a dork!' edits probably don't merit a block unless they are persistent."
Any thoughts? --Ixfd64 11:30, 13 May 2009 (UTC)
- FYI, there are no deleted user contributions. DAVilla 17:57, 13 May 2009 (UTC)
- Yes, Many. Look in the archives to this page for numerous similar discussions. Essentially problems occur, either:
- Deliberately and unconstructively (as in this case. in which case the editor is blocked or ignored).
- Through lack of understanding of Wiktionary (in which case the editor is welcomed, and their mistakes are explained).
- As, in the first case, the person was not trying to help, there is (from experience) little point in trying to communicate with them. There are occasional mistakes in classifying editors between the two, but these are rare. Conrad.Irwin 12:21, 13 May 2009 (UTC)
- A short block serves two purposes. 1) It stops further vandalism. 2) It serves as a record that a person (or ip address) has vandalised before - so any subsequent vandalism can be dealt with more severely. SemperBlotto 12:26, 13 May 2009 (UTC)
- Question: knowing that mistakes do happen, where an individual is blocked for an edit that is interpreted as vandalism but was not malintentioned (I remember a case where a user had actually reverted vandalism and then was blocked himself, having been mistaken in identity with the vandal in a very sloppy case of detectivework), how can the record you speak of be amended to reflect their amended status as non-vandal, so that a patrolling admin might not so readily assume otherwise? DAVilla 17:57, 13 May 2009 (UTC)
- Block him again, for a second, with a note indicating that in your opinion the revious block was mistaken. This would be best coming from the original blocking admin, natch.—msh210℠ 20:41, 13 May 2009 (UTC)
- My experience is that, when reverted and otherwise ignored (not blocked nor warned), a vandal stops very quickly (in most cases). This might be the most effective way to deal with them. If they insist too much, they should be warned, but they should also be strongly encouraged to contribute (in a constructive way). When nothing else works, they should be blocked (but blocking does not work with vandals contributing with many different IP addresses...).
- I feel that a new helpful principle could be Vandals want to play. Don't play with them!. Lmaltier 20:50, 13 May 2009 (UTC)
Random page per language
Connel's random page per language has been dead for a while and I've been using my Toolserver account a fair bit lately so today I whipped up my own implementation:
http://toolserver.org/~hippietrail/randompage.fcgi?langname=English
or
http://toolserver.org/~hippietrail/randompage.fcgi?langcode=en
Just replace "English" with any language name or "en" with any language code used in the English Wiktionary.
It only knows about page titles from the last official dump released: 20090509
It does not yet work with language codes.
It does not yet automatically update when new dumps are released.
It has an incomplete "special page":
http://toolserver.org/~hippietrail/randompage.fcgi?langs
Have fun with it! — hippietrail 08:36, 15 May 2009 (UTC)
- Awesome, thanks! FYI, thanks to Robert Ullmann's coding and Amgine's (I think) hosting, there are daily dumps available at http://70.79.96.121/w/dump/xmlu/.
- BTW, is it intentional that it generates URIs of the form http://en.wiktionary.org/wiki/matere#Middle%20English?rndlangcached=yes instead of, say, http://en.wiktionary.org/wiki/matere?rndlangcached=yes#Middle_English?
- —RuakhTALK 14:45, 15 May 2009 (UTC)
- Yes I know about the daily dumps thanks but I still need to set up tools to download them and index them automatically with various error checking on the Toolserver.
- No the messed up fragment vs query was a last minute hack to see whether keeping all the words files in memory on the toolserver might use up too much resources and get it killed. Anyway I've fixed it now and thanks for pointing it out to me! — hippietrail 15:35, 15 May 2009 (UTC)
Non-Latin text seems to be broken. lang=uk takes me to pages like ÑлÑжниÑÑ?rndlangcached=yes#Ukrainian. —Michael Z. 2009-05-15 16:43 z
- The redirector isn't doing URL-encoding, so I guess it depends how your browser's HTTP implementation (and possibly those of any intervening proxies) handle UTF-8 data in the Location header. It works fine for me in FF3 and IE7 on WinXPPro. —RuakhTALK 17:25, 15 May 2009 (UTC)
- Should be fixed now. Let me know if not. — hippietrail 04:17, 16 May 2009 (UTC)
- Re: ISO-8859-1: Technically yes, but it should be moot, in that there's no need for the browser to do any sort of conversion (except perhaps its own URL-encoding, since the redirecting server obviously failed in that regard). There's no reason Safari should re-UTF-8-ify as it URL-encodes the byte-string. (But, I'm not really blaming it: this is a GIGO kind of situation.) —RuakhTALK 15:23, 16 May 2009 (UTC)
- You can select a specific language with http://toolserver.org/~hippietrail/randompage.fcgi?langname=Russian. —Stephen 15:58, 16 May 2009 (UTC)
Previous talk:
- Wiktionary:Tea_room/2007/November#Category:Filmology
- Wiktionary:Beer parlour/2009/January#Category:Filmology
- #Category:Filmology, Template:filmology
Individual editors have expressed preference for Category:Cinema and Category:Film, but no one has come to any agreements. The current category name is plain wrong, so it must change. A new category name could be changed again anyway if we dislike it.
I'm going with the experts. OED labels this subject Cinematogr., so I'll now move this to Category:Cinematography. —Michael Z. 2009-05-15 17:34 z
- I haven't followed the previous discussions regarding this matter, but I'm quite sure that cinematography has a significantly narrower range of meaning than, say, film, or filmmaking, or cinema. "Cinematography" ordinarily refers explicitly to the photographic artistry and photographic technical processes employed in filmmaking. Consider that the academy award for Best Cinematography is only one of a great many academy awards in the diverse achievement areas (sound, costuming, editing, writing, etc.) which come together in the making of a motion picture. The "Filmology" category contained far more terms than simply terms relating precisely to the photographic aspect of filmmaking. I think Michael has jumped the gun here and that this change should be reconsidered. -- WikiPedant 22:48, 15 May 2009 (UTC)
- Or maybe you were asleep at the wheel when this was discussed over a week and then sat idle in the Beep for another 10 days. I've now acted on consensus, or rather mostly disinterest, and the discussion
hereat WT:RFDO#Category:Filmology is merely whether to delete an empty incorrect category page.
- Or maybe you were asleep at the wheel when this was discussed over a week and then sat idle in the Beep for another 10 days. I've now acted on consensus, or rather mostly disinterest, and the discussion
- By the way, the name of an awards category of the American Academy of Motion Picture Arts and Sciences doesn't define cinematography. —Michael Z. 2009-05-15 23:39 z
- Sorry I don't follow the project page discussions with sufficient regularity to meet your standards, but the fact remains that swapping "Cinematography" for "Filmology" was just plain mistaken. "Cinematography" has a much narrower range of meaning. As for the OED, I just spot-checked the OED entries for "pan", "out-take", and "montage" and found them all contextualized as Film. "Film", "Filmmaking", "Motion pictures", or "Cinema" would all be vastly more accurate substitutes for the defunct "Filmology" label than "Cinematography". PS -- I note that you have just rewritten the defn at cinematography, construing the term as a synonym for "filmmaking". Your defn is self-serving and inaccurate; it does not conform to the defns for "cinematography" in the OED ("the use of the cinematograph; the art of taking and reproducing films"), the Random House Dictionary ("the art or technique of motion-picture photography") or Wikipedia ("the making of lighting and camera choices when recording photographic images for the cinema"). -- WikiPedant 04:36, 19 May 2009 (UTC)
- 1989 OED entries like zoom n. have Cinematogr. Looks like OED has changed the label to Film in 2002/2008 entries. Sorry I missed those. There's no basis for saying that cinematography is narrower than filmmaking; obviously OED thinks they are close equivalents, and film is currently an improvement.
- Your “self-serving” accusation is pretty rank. I improved an incorrect and naïve definition. Please don't try to write lexicographical definitions by copying from Wikipedia.
- The fact is that for two years the category name was wrong. (Have you even read what filmology actually is?) After 18 months of discussion, this community was unable to agree on anything that was right. I tried yet again to get some interest and find consensus, but that's not going anywhere. So I did some significant work to correct it. Maybe I didn't make the best call, but at least now it's not wrong and we all look a bit less stupid. So because I actually did something to correct a dumb mistake, the trolls come out of the woodwork to tell me what a dick I am.
- The discussion is still open. Go ahead and get consensus for your favourite version of cinematography/cinema (that's short for cinematograph)/film/filmmaking/movies/visual media/whatever. Let me know when you do, and I'll even help move the contents of the category. In the meantime, do something useful instead of criticizing me. —Michael Z. 2009-05-19 05:06 z
- I'd say let's go for "Film". Does anyone think "filmology" is better than "film" or that "cinematography" is better than "film"? As regards "cinematography", WikiPedant and EncycloPetey[2] expressed their misgivings about the narrowness of the term. While "film" also denotes a thin layer, I don't think anyone is about to create a category for thin layers. Let's avoid trying to find the best option, and see if we can agree on a proposal that, while perhaps imperfect, is good enough: "Film". Agreed? --Dan Polansky 18:47, 19 May 2009 (UTC)
- Yes, "Film". -- WikiPedant 23:14, 19 May 2009 (UTC)
- I agree. Ƿidsiþ 08:18, 20 May 2009 (UTC)
- I'll be happy with film too, by the way. —Michael Z. 2009-05-24 18:56 z
Missing transliteration in the translations or entries
What's the method of requesting the transliteration in the existing translations? Or how do you add a translation where transliteration is unknown/not ceratin for Arabic, Korean, etc. As an example, I don't have my paper dictionaries handy. Could we have something like this?
Anatoli 04:37, 19 May 2009 (UTC)
- Without the ' ' for preference, maybe even just leave it blank so as to not confuse the unfortunate people who see □□□□□ even more (maybe not for arabic, but there are some unsupported languages). On a second note, I was intending to write an extension (either for editor.js or for MediaWiki) to allow for automatic transliteration, is that possible for Arabic? Conrad.Irwin 13:44, 19 May 2009 (UTC)
- I put '???' to avoid confusion with left to right problems, looked messy with Arabic. Instead there could be something like Please add a transliteration, if you can.
- No, automatic and accurate Arabic transliteration is impossible. Even with a smart program, which would look up words in a dictionary (there is no reliable one available), there are many homographs. The issue (briefly) is with inserting correct unwritten short vowels or identifying absence thereof and geminating (doubling) consonants. The long vowels may be read as consonants or diphthongs, also depending on the preceding/following unwritten short vowels. Some text-to-speech engines do a good job with Arabic but they must be analysing some grammar as well, not just individual words. They are not perfect, anyway, at this moment. Anatoli 19:52, 19 May 2009 (UTC)
- I wonder if it could be automated at least for verb translations, where (assuming the bot knows some grammar) there are fewer possible vowel combinations? But maybe it's not worth the risk of errors. —RuakhTALK 20:03, 19 May 2009 (UTC)
- It could be automated if arabic words were written with all vowels - as they should be in the wiktionary. There is a category for entries lacking vowels Category:Entries which need Arabic vowels, by the way. Beru7 20:41, 19 May 2009 (UTC)
- Trouble is, if you pick up the word from Google translate or many other online dictionaries or simply a text, there are no vowels written. My preference is not to write all Arabic short vowels here but provide the romanisation, that way the Arabic words look the way they look in the real world but there is no problem with the pronunciation, as there is the phonetic guide. The romanisation, as opposed to Arabic vowels, will also unambiguously show marginal sounds, which only appear in loanwords or dialects - /o, e, g, p, v, tʃ, ʒ/, which Arabic vowels cannot do, also the issue with ﺝ and ﻍ where they can be used to represent /g/ instead of the expected /ʤ/ and /ɣ/ in loanwords or Egyptian Arabic (ﺝ). Anatoli 22:39, 19 May 2009 (UTC)
- What you haven't noticed, maybe, is that page titles are written with no diacritics for this reason exactly. That means you can cut and paste into the search box and land on the word page. There are already thousands of entries in the arabic section that have been written that way, so I don't think it is time to change that except if there are very, very good reasons to do so. And let's leave dialects out of this discussion: they have their own sections. Beru7 13:28, 20 May 2009 (UTC)
- Oh, please don't do that. It just looks messy, and could be mistaken to mean that you're not sure if that's the right translation. An admin would move it to TTBC, a newbie would mimic that with European terms they think might be right. DAVilla 18:37, 20 May 2009 (UTC)
- I don't think there's a specific way to do this (though maybe we should create one). I used to append
{{rfscript|Arabic}}, which adds the entry to Category:Entries which need Arabic script, and add a comment that the issue is actually the opposite; but now that we have{{attention|ar}}, which adds the entry to Category:Arabic words needing attention, I usually use that instead — it's less precise, but also less inaccurate. But neither approach adds any sort of "transliteration needed" message to the entry. —RuakhTALK 20:00, 19 May 2009 (UTC)
- We have the category Category:Arabic words lacking transliteration. That can be used as is, or a template could be written to evoke it. —Stephen 18:56, 20 May 2009 (UTC)
- Perhaps these should be used more often. As for automatic transliteration, it is possible for a number of other scripts with some exceptions, including Cyrillic-based languages. Anatoli 22:39, 19 May 2009 (UTC)
- Still, automatic transliteration can be very useful for Arabic too. It can transliterate consonants, and leave the vowels to add by hand. E.g., it can give škr for شكر, which can be easily tweaked to šukr by hand. That way you won't have to use the unscientific Arabic transliteration system you employ now (as far as I can remember, the easyiness of typing, i.e. sh for š, was the main argument in favor of it). --Vahagn Petrosyan 10:32, 20 May 2009 (UTC)
- There is nothing "unscientific" about using sh instead of š. It is a commonly used transliteration for shin, used in many scientific works, and by the library of congress. Beru7 13:28, 20 May 2009 (UTC)
- I consider that system to be "unscientific" for two reasons:
- 1) It transliterates many Arabic letters with two Roman ones. Theoretically, you have no way of knowing whether sh is IPA: /ʃ/ or IPA: /sh/, or gh is /ɣ/ or /gh/. It's ambiguous.
- 2) It's an anglicization, not a romanization. shukr will have to be changed to chukr in French Wiktionary, and we're supposed to be the papa-wiktionary from where everybody else can plunder everything they wish, without caring to make modifications. --Vahagn Petrosyan 13:50, 20 May 2009 (UTC)
- "Unscientific" may not be the best choice of words. But the system is imprecise and ambiguous. Dictionaries which use digraphs to transliterate Arabic utilize other conventions to disambiguate, such as italics or underscoring, neither of which are copy&paste compatible online. Better to have a one-to-one Arabic-Latin transliteration. kwami 18:09, 20 May 2009 (UTC)
- To be fair, I just noticed WT:AA proposes to use (-) to distinguish between sh and s-h. Still, this is not the best solution and there is the problem of transliterating ع with 3 which is unscientific. Anywho, we are not here to discuss the problems of Arabic transliteration systems, which can be easily solved if and when Conrad develops his automatic transliteration tool.
- (To Anatoli) You can manually add the English entry into Category:Arabic words lacking transliteration or ask Conrad to tweak the Editor to do that automatically whenever transliteration bar is left empty. --Vahagn Petrosyan 19:12, 20 May 2009 (UTC)
- I used the transliteration because this was the agreement between at least, three user. Why didn't you guys take part in the discussion (Wiktionary_talk:About_Arabic)? If the decision is to change, I will follow. I don't think automatic transliteration is a good idea for Arabic and Hebrew because we will mislead readers with the incomplete pronunciation. Perhaps, it could be used to assist typing the transliteration but the editor should know the pronunciation, otherwise, they may leave it as škr. The automatic transliteration could be used for Korean, though (I know the formula to decompose the Hangul characters into Jamo components), Devanaghari, Cyrillic scripts. As for my original question, those templates can be used for Arabic entries, not for the translation. I will be away for two weeks. May not reply any answers soon. Anatoli 22:22, 22 May 2009 (UTC)
Arabic transliteration
Split from previous topic. Should we discuss this? The discussion is very quiet but I don't want to end up in a position to fix all my translations. So if you have something to say, please do. Ideally someone who cares and is going to actually take part (or has been) in Arabic translations and creating/editing entries.
There are not enough Roman letters to transliterate Arabic one to one and there are multiple standards. We also have multiple de facto standards in wiktionary. I support User:Beru7's suggestion to simplify with some reservations, especially using "3" and -a(t). But let's revive the discussion. Anatoli 01:39, 22 July 2009 (UTC)
- IMHO, saying what is right in Arabic is often difficult as many respectable sources may show conflicting information, not just about the pronunciation but even spelling (even when referring to standard, not vernacular Arabic). There are different opinions about case endings or initial alif following it, transliteration of "al-" in front of "the Sun letters", spelling of hamza over and under alif. As a result, we have variant spellings, pronunciation and transliteration. Dialectal words are mixed with Literary Arabic, if they become too common and penetrate the written language. We could use the best known or the most common. Anatoli 01:57, 22 July 2009 (UTC)
Slow-loading, really big entries
I today found my first ordinary article that gave the "too big for some browsers" warning. It had taken ten seconds or so to load on my broadband connection. This miner's canary of entry was water. The translation section is huge. It might not be too soon to consider some way of accommodating this. For anyone without broadband, this would probably be inaccessible. I doubt that we can assume that global broadband availability will make this moot. Would we need a separate translation space? That would seem only temporary palliative. DCDuring TALK 15:10, 20 May 2009 (UTC)
- A custom translation page, analogous to the citation pages, might be a good idea. We could give a Translation subheading with a link and a warning that it's a large page. kwami 18:04, 20 May 2009 (UTC)
- There are many solutions to this, my favourite would be to load them on-demand when the user clicks "show". Given that only 0.00047% of our pages are above 20kb (which is on about 30 times smaller than WT:BP), I don't think this is a pressing problem. I don't think that there are any solutions with no negative side-effects, so probably should be ignored for the moment. Conrad.Irwin 20:31, 20 May 2009 (UTC)
- I think a water/Translations page would be a fine solution. They will be rare. bd2412 T 00:35, 21 May 2009 (UTC)
- There are many solutions to this, my favourite would be to load them on-demand when the user clicks "show". Given that only 0.00047% of our pages are above 20kb (which is on about 30 times smaller than WT:BP), I don't think this is a pressing problem. I don't think that there are any solutions with no negative side-effects, so probably should be ignored for the moment. Conrad.Irwin 20:31, 20 May 2009 (UTC)
- (...with not one but two ugly boxes linking to Wikipedia! and a number of definitions that say "in plural".) DAVilla 18:31, 20 May 2009 (UTC)
- It would be nice of one of our tech people could design something that would allow the user to specify, perhaps in their css file, which languages to show (or not show) in translation boxes to avoid the nightmare of water and similar situations... — [ R·I·C ] opiaterein — 17:45, 3 June 2009 (UTC)
- Sadly, CSS cannot be used to prevent parts of the HTML from being downloaded. I think the ideal would be Conrad's suggestion, if we can make it work without too many problems. My thoughts on problem-minimization are as follows:
- For Ajaxy readers, it should look and behave just as a normal nav-bar, except for load-time between when the user clicks "show" and when the translations actually appear. (This will require some forethought, but is not particularly difficult.) For non-JS or non-Ajaxy readers, the "show" link should be an actual link to the separate wiki page hosting the translations for the section. (This one also should not be too difficult, but note that the "show" link is currently added by JS, so this will require a bit of work. Incidentally, note that this requirement means that the name of the separate wiki page has to be provided manually to the
{{external-trans-top}}template or whatever; it can't just be inferred intelligently by JS code. Which, to be honest, is probably a good thing; there will be enough magic anyway.) - In the raw wiki code (what you see when you edit), contents of a given translation table will appear almost as normal, but preceded by something like
<includeonly><section begin="translations_foo_bar"/>
and followed by something like<section end="translations_foo_bar"/></includeonly>
. This will hopefully enable editors to edit the translations section without worrying too much about how it's implemented, and bots and external tools to ignore it entirely. (Drawback: it's likely that editors will sometimes copy this boilerplate code without understanding it, and without understanding why their translations don't show up. One option is for the Ajaxy code to display some sort of error message that tries to explain it, but this is basically a lost cause. Users don't read error messages, ever. There's an urban legend about a user having once read an error message, but it was debunked by Snopes.com.) - A separate wiki page, probably in the Appendix: namespace, will consist entirely of
{{#lst:baz|translations_foo_bar}}. The aforementioned Ajax can load this using /w/api.php?action=parse&page=Appendix:Translations/baz/foo_bar or whathaveyou.
- For Ajaxy readers, it should look and behave just as a normal nav-bar, except for load-time between when the user clicks "show" and when the translations actually appear. (This will require some forethought, but is not particularly difficult.) For non-JS or non-Ajaxy readers, the "show" link should be an actual link to the separate wiki page hosting the translations for the section. (This one also should not be too difficult, but note that the "show" link is currently added by JS, so this will require a bit of work. Incidentally, note that this requirement means that the name of the separate wiki page has to be provided manually to the
- But I haven't used Ajax all that much, nor really delved into the innards of labeled section transclusion; I welcome the opinions of anyone greasier. (And for that matter, the opinions of anyone else with opinions. I'm not picky. :-)
- —RuakhTALK 18:54, 3 June 2009 (UTC)
- This may raise hackles, but why not just have translations in, say, the top ten languages by number of speakers on the entry page, and relegate other translations to a subpage? bd2412 T 04:33, 6 June 2009 (UTC)
- Sadly, CSS cannot be used to prevent parts of the HTML from being downloaded. I think the ideal would be Conrad's suggestion, if we can make it work without too many problems. My thoughts on problem-minimization are as follows:
<BLINK><RED><BIG>
The Wiktionary Logo renewal plan has reached the stage where it is open for nominations. Rather than kicking up a fuss about the logo that Wiktionary gets given by other people. Get Involved Now. Conrad.Irwin 12:47, 21 May 2009 (UTC)
</BIG></RED></BLINK>
- I've had a new idea for a logo and made a quick mockup. See the favicon topic. — hippietrail 03:45, 12 June 2009 (UTC)
MICRA's version of Roget's thesaurus
I have uploaded MICRA's version of Roget's thesaurus here:
A downside: the six subpages are very long. Yet, here it is, the complete MICRA and Roget's thesaurus wikilinked to Wiktionary.
If you like the thesaurus, it can be moved to appendix space. Enjoy. --Dan Polansky 16:15, 22 May 2009 (UTC)
Mathematical definitions
I was wondering if it were possible (even theoretically, if not practically) to define mathematical terms using English language sentences rather than mathematical symbolism. For example, I would like to be able to define (deprecated template usage) hypoelliptic and all I have to go on is the Wikipedia article w:Hypoelliptic operator (which is fairly typical of the genre). SemperBlotto 07:24, 25 May 2009 (UTC)
- I'm afraid this is an example where defining is just not possible for someone without knowledge of fairly advanced maths. Possibly, the term would be based on a calculus-related definition of (deprecated template usage) elliptic (cf. elliptic operator). Circeus 11:45, 25 May 2009 (UTC)
- We certainly can't convey what something like this is in a dictionary definition. Is it possible to express its relationship to other mathematical or other entries: giving the various nyms and the branches of theory and application where it arises? I certainly didn't get much out of the WP article in that regard, so I don't know how you could get the information. BTW, I couldn't read the linked PlanetMath article, but it might have more. DCDuring TALK 12:05, 25 May 2009 (UTC)
- Yes, it's possible to word such a thing using English, and one's ability to do so is often a pretty good marker of his understanding of the subject (assuming he knows English: otherwise it's not, of course). Wikipedia's explanation of w:Frobenius number is:
- Given n natural numbers with greatest common divisor 1, find the largest natural number that can not be expressed as a non-negative integer combination of these n numbers. For a given set this largest number is referred to as the Frobenius number .
- Our definition of Frobenius number doesn't use symbols:
- The greatest integer that cannot be formed as a sum of specific coprime positive integers.
- It is less precise (refers to a "sum" of the numbers without specifying that a number can appear more than once in that sum, which is frankly incorrect and should be fixed) but is fairly decent for a dictionary entry.—msh210℠ 01:40, 26 May 2009 (UTC) ...Now fixed. —AugPi 03:11, 26 May 2009 (UTC)
- How does this fit in with our authority-defying reliance on how words are actually used? We seem willing to defy many scientific and international authorities in technical fields. Should we be altering WT:CFI for some or all of the fields where technical correctness or voted-on standards exist? DCDuring TALK 02:12, 26 May 2009 (UTC)
- I think that if the usually given definition of Frobenius number is as stated above, and someone uses it without any context indicating that that's likely (or surely) not the definition he's using, then it counts as a good cite. (Where two conflicting definitions are common, which happens in math, the cites, I think, should be clearly of one sense or the other.) Moreover, I think that the current CFI allow for this. Does all that seem reasonable?—msh210℠ 02:37, 26 May 2009 (UTC)
- Mathematics terms are in an even more restricted realm than most specialized terms. I hadn't noticed many mathematical terms being challenged on RfD or RfV, so I wonder about how it will work when it happens. Perhaps the topic=mathematics parameter will gain some use. We lack many of the most basic terms in statistics, let alone stochastic integrals. I hope we have good mathematical definitions for terms like "obvious", "trivial", and "an exercise for the reader". DCDuring TALK 03:05, 26 May 2009 (UTC)
- I think that if the usually given definition of Frobenius number is as stated above, and someone uses it without any context indicating that that's likely (or surely) not the definition he's using, then it counts as a good cite. (Where two conflicting definitions are common, which happens in math, the cites, I think, should be clearly of one sense or the other.) Moreover, I think that the current CFI allow for this. Does all that seem reasonable?—msh210℠ 02:37, 26 May 2009 (UTC)
- How does this fit in with our authority-defying reliance on how words are actually used? We seem willing to defy many scientific and international authorities in technical fields. Should we be altering WT:CFI for some or all of the fields where technical correctness or voted-on standards exist? DCDuring TALK 02:12, 26 May 2009 (UTC)



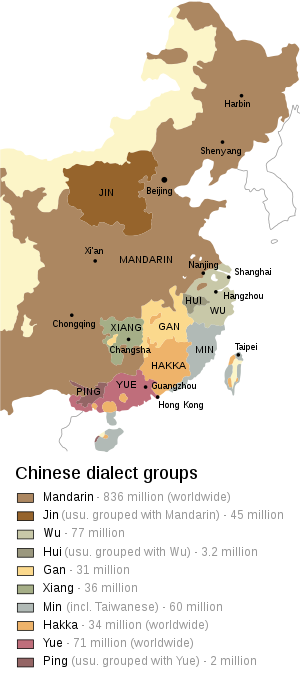{kind=link}
- The mathematical definition for those would be, respectively: "There's probably an error here," "You can't see this, but I'm waving my arms vigorously", and "I was too lazy to write out a proof." :P --EncycloPetey 03:32, 28 May 2009 (UTC)
- Not an error, necessarily, but more than likely an unnamed assumption, in all honesty. The other two are dead on, so why the tongue? DAVilla 02:30, 31 May 2009 (UTC)
- I've extended a request for assistance to WP:WPMATH in writing layman's definitions of technical terms (giving (deprecated template usage) hypoelliptic for the example) and locating interesting quotations for terms like (deprecated template usage) sphenic number below. Circeus 02:45, 3 June 2009 (UTC)
How to handle "see also"
What is the recommended way to do "see also", using an also template at the top of the page or a see also section in the body? I prefer the section in the body, but I see the other way done here and there as well. -- dougher 01:03, 27 May 2009 (UTC)
- Generally
{{also}}is for entries that have very similar titles — basically a "you may have been looking for this instead" — whereas a ===See also=== section is for entries on other words that are connected in some way — basically a "you may be interested in this as well". For example, [[a]] might use{{also}}to link to [[à]], but ===See also=== to link to [[the]]. The two are not mutually exclusive; an entry can easily have both, and many do. In fact, I can imagine an entry linking to the same other entry in both places; for example, right now [[there]] doesn't link to [[there-]], but I think both{{also}}and ===See also=== would be appropriate ways for it to do so. —RuakhTALK 01:18, 27 May 2009 (UTC)
- To add to that, keep in mind that
{{also}}appears above the first language section, so it cannot be language specific. Variations like capitalization, spacing, and hyphenation are common. In contrast, ===See also=== is specific to the language, and ====See also==== to the part of speech. DAVilla 07:57, 27 May 2009 (UTC)
- To add to that, keep in mind that
- I agree. The fr.wiktionary policy is to mention only words with the same letters in the same order (but there may be differences in capitalization, spacing, diacritics or special characters (such as , - or /)). Other similarities are not considered. This rule is not subjective, and a bot could exploit dumps to do the job. Lmaltier 18:17, 28 May 2009 (UTC)
- We also allow double letters like nam and naam, or at least it's come up before without objection. But that isn't subjective either. DAVilla 04:15, 29 May 2009 (UTC)
- No, but only if rules are clearly stated (very similar is subjective). Lmaltier 08:50, 1 June 2009 (UTC)
- We also allow double letters like nam and naam, or at least it's come up before without objection. But that isn't subjective either. DAVilla 04:15, 29 May 2009 (UTC)
Latin orthography
I'm trying to find some sort of consensus (or indeed consensvs) on how to deal with Latin spellings on the Wiktionary. It's difficult with dead languages, especially one that existed for at least two thousand years and over half the globe. I suppose I'm talking here about things like (deprecated template usage) jocus and (deprecated template usage) iocus, which if I'm right should be (deprecated template usage) IOCVS in traditional Latin. A couple of sources to get us start: w:Latin spelling and pronunciation and Wiktionary:About Latin. Mglovesfun 09:54, 27 May 2009 (UTC).
Having just read those two, what should we do with things like (deprecated template usage) jocus, alternative spelling, or just a redirection? Mglovesfun 09:57, 27 May 2009 (UTC)
- They should not be redirects, see WT:REDIR#Redirecting_between_different_spellings_of_words, so they should be alternative spellings pages. Conrad.Irwin 10:24, 27 May 2009 (UTC)
- Are you thinking about which form should be the main one? For the benefit of users one would want to minimize the number of server-hitting clicks to get useful content. Latin terms could be reached from a search or from links, especially from etymologies. I would bet that the etymologies are a high percentage (without much fear of being contradicted by facts of which I have seen none). Whatever they now link to should remain the entry with the main content. The expectation of readers to see lower case letters is pretty strong. Putting a word in all caps is considered visual SHOUTING. DCDuring TALK 15:28, 27 May 2009 (UTC)
- We should decide — or have — on one standard (e.g., always using i, never j), and always soft-redirect (i.e.,
{{alternative spelling of}}) from the other if attested.—msh210℠ 16:12, 27 May 2009 (UTC)
- This has already been decided Wiktionary:About Latin#Prefer spellings with I; do not use J, combined with WT:REDIR's policy on not using redirects for alternative spellings leave no alternatives to be considered. Conrad.Irwin 16:16, 27 May 2009 (UTC)
- The policy on I/J seems to contradict the policy on V/U. This should probably be looked into again. And while it is interesting to consider which should be the main spelling, the policy excludes other attestable spellings, which feels very wrong to me. There would always be at least two, the uppercase spelling that never uses J or U, and the lowercase spelling that substitutes these with the modern consonant/vowel expectations. When there is a substitution to make, there is also the lowercase variant where the spelling is unchanged, and potentially even a fourth common spelling where vowel V changes to U but consonant I does not change to J, if a word were to have both. Current practice prefers the latter when it exists, which could be very confusing indeed. It also picks
what is probably the least likely attestable form of the word,a particular modern spelling without macrons. I don't believe macrons would actually double the number of representations. Certainly the uppercase forms need not have them, nor I'm guessing their lowercase counterparts that do not use J/U substitutions. But if it's printed in any of these ways, I would expect to see a soft redirect. DAVilla 17:00, 27 May 2009 (UTC)
- The policy on I/J seems to contradict the policy on V/U. This should probably be looked into again. And while it is interesting to consider which should be the main spelling, the policy excludes other attestable spellings, which feels very wrong to me. There would always be at least two, the uppercase spelling that never uses J or U, and the lowercase spelling that substitutes these with the modern consonant/vowel expectations. When there is a substitution to make, there is also the lowercase variant where the spelling is unchanged, and potentially even a fourth common spelling where vowel V changes to U but consonant I does not change to J, if a word were to have both. Current practice prefers the latter when it exists, which could be very confusing indeed. It also picks
- Re: "The policy on I/J seems to contradict the policy on V/U": I don't think so. My understanding is that modern printings of Latin works typically use English-style capitalization and distinguish U from V, but typically do not use macrons and do not distinguish I from J. So, we seem to be in line with modern standard practice. (Which is not to say that all-capitalized spellings, or spellings with Js or macrons or vocalic Vs, don't warrant some sort of redirection.) —RuakhTALK 17:27, 27 May 2009 (UTC)
- That's good to know. After reading EncycloPetey's response below, I take back most of what I said. DAVilla 03:18, 28 May 2009 (UTC)
- [e/c] The About Latin page says use only i, never j. That is (as I understand it), not even to soft-redirect. I recall a certain eminent Latin contributor's saying we should not have such soft redirects, and seem to recall his deleting them. I think that that's not the way to go, and if About Latin is policy I think policy should change (slightly). People will look for judico.—msh210℠ 16:55, 27 May 2009 (UTC)
- Wiktionary:About Latin#Prefer spellings with I; do not use J, I assume there are quite a few editors of this paragraph as it seems to contradict itself a lot. It says 'do not use J' in the title, and then changes its mind later on. Plus 'prefer I' - well if you don't us J, surely I is all that's left anyway? So it's either redundant or confusing, in fact probably both. Mglovesfun 22:37, 27 May 2009 (UTC)
I’m glad to see this issue raised, as it’s one that I also think is not best dealt with at present. I take the position that the inclusion of Latin words should be according to the (qualified) criterion of attestability. Take, for example, IVVENIS, which is attestable as IVVENIS, ivvenis, JUVENIS, juvenis, IUVENIS, iuvenis, iuuenis (but not *IUUENIS), juuenis (but not *JUUENIS), JVVENIS, and jvvenis (all the hits from sources which are purported write the term with ‘J’/‘j’ only are scannos AFAICT) — that’s ten different forms (and that’s without counting forms written with diacritics like breves and acute accents, such as juvénis &c.).
Counting just character substitutions, we have (at least) capitals–lower case, all I–I/J, all U–U/V–all V, AE–Æ–Ę–E & OE–Œ–Ę–E (<Ę> = e caudata), marca–bare characters–breves–both, acute–grave–zero-stress-accented, ſ/s–s only, &c. (2 × 2 × 3 × 4 × 4 × 3 × 2 × n… = >1,152 hypothetical variations); whilst it is certain that no Latin term will have over a thousand attestable alternative forms, the above does show the extraordinary potential and significant actual variation that at present we simply deny.
Many of those variables don’t really matter — viz. capitals–lower case, e caudata, and vowel-length marking (users are unlikely to search in all-caps, the e caudata is extremely rare, and macra / breves seldom ever occur outside textbooks) — but others do — I–J & U–V and the digraph–ligature–monograph trichotomy especially, whereas the use of the long ess and stress marking also cannot be simply dismissed as vanishingly rare or as unsearchable.
Rather than just assume that our users will know to edit automatically words they encounter to conform with our schema, we should provide them with information that reflects the complexity of the true picture of changing Latin usage over the millennia; such an approach would be far more in line with the ambition to include “all words in all languages”. We can still have our entries where they are at the moment, but we need to allow soft redirects to them from their various variants (in fact, it should be seen as A Good Thing™ that we have a pretty clear and uncontroversial policy governing whereat to house a Latin term’s “main entry”). † ﴾(u):Raifʻhār (t):Doremítzwr﴿ 23:43, 27 May 2009 (UTC)
- The Latin letters I and J are very, very late orthographic variants of the same letter, and not alternative spellings. Even in English, "long-I" (J) is used in some antiquated texts. In Latin it does not appear until very, very late in the language. The difference between iuvenis and juvenis in Latin is akin to the difference between cat and cɑt in English. If we're going to have entries for alternative orthographies of the same letter for words in the same spelling, then we should do that with all languages. Modern Latin dictionaries, textbooks, and the like do not use "j" precisely because it was not even thought of as a letter until after the Renaissance. Modern ideas about whether the letters are separate notwithstanding, we should judge the language by its internal rules, just as we do for other issues such as "sum of parts" discussions. Shoehorning this typography into every Latin entry would be like requiring every English entry with an "s" to have a long-S form; every entry that was capitalized in Victorian literature to have a capitalized counterpart; and every English word with an "a" or "g" to have variant entries with a single-loop "ɑ" and a double-loop "g". When we start doing that with English, French, etc., then it will be appropriate to do such things in Latin as well. Personally, I think such an efort is counterproductive and would make Wiktionary look foolish. By contrast, the Latin letters U and V began to diverge comparatively early. By the early Medieval period, their typography was distinct. Modern Latin dictionaries, textbooks, and the like routinely distinguish between the two.
- Let's look at an analogous (sort of) example in English. I have, next to me, a facsimile of Shakespeare's Romeo and Juliet as published in the First Folio edition. The title at the top of the play proclaims "THE TRAGEDIE OF ROMEO AND IVLIET," so do we need an entry for Ivliet? Across the tops of the next few pages, the title is given as "The Tragedie of Romeo and Iuliet," so do we need an entry for Iuliet? Mixed in among these page headings later are ones that give the title as "The Tragedie of Romeo and Juliet," but the spelling Iuliet is the most common one in the text of the play. In the same play, I find Iohn (for John), subiects (for subjects), Vncle (for uncle), seruingmen (for servingmen), giue (for give), mou'd (for moved), vs (for us), moue (for move), ſerue (for serve), and all of this (and more) in the first page of the play. --EncycloPetey 01:16, 28 May 2009 (UTC)
- If we're going to judge it by internal rules, then why do we choose i as the class representative for I, J, i, and j? You've chosen the middle/late Medievel spellings with regard to the U/V distinction. I/J distinction did not come about until the Renaissance, and we couldn't have converted to writing Latin in minusules earlier than that, did we? In English, full majuscules are an alternative capitalization for titles, but it was the standard orthography for Latin.
- What alternatives are there for variations in capitalization and orthography? I know if the page exists we use a See also, but what if it doesn't exist? How smart is Did you mean? DAVilla 03:12, 28 May 2009 (UTC)
- Latin has been written with miniscules since miniscules have existed (usually credited to scribes under the reign of Charlemagne). If we're going to worry about that, then we should run all ancient Greek words together since they typically didn't put spaces between words; nor did they capitalize according to modern usages. Shall we keep piling on questions without answering any? One possibility is to have an unlinked list of orthographic variants, perhaps in a template. These would be found using a site search. --EncycloPetey 03:24, 28 May 2009 (UTC)
- I guess I just don't understand ancient languages. To me something is lost, not gained, by adding spacing, changing capitalization, or otherwise interpreting a text differently than the way it's written.
- You noted that orthographic variants exist in English etc. I'm not sure a template would be the best idea there, but these choices demanded by Latin may necessitate it for Latin if a more encompassing solution can't be obtained. DAVilla 17:35, 28 May 2009 (UTC)
- Re: "interpreting a text differently than the way it's written". Unfortunately, this is routinely done for any text whose spelling, puctuation, etc. is not considered "standard". Shakespeare's plays are almost never encountered with their original spellings and capitalizations (even on Wikisource!) unless you deliberately go hunting for a facsimile text. I spent several months one summer looking for an unedited copy of Milton's Paradise Lost. The problem is even greater with Latin, where most available texts have been edited to norms of spelling chosen by the editor according to standards of the day in which the text was published. I don't have any copies of Classical texts that I would trust to have preserved a Classical orthography with any fidelity. I do have copies of a number of medieval and Renaissance texts in Latin where the editor went to great pains to preserve oddities of the hand in which the documents were written.
- Neither is the problem limited to Latin. Czech publications are notorious for silently standardizing and normalizing spelling of medieval reproductions. Furthermore, if you ever look at old handwritten manuscripts, then you begin to appreciate all the editing done to make the content accessible. Reading medieval hands is an art unto itself, and there are many marks and abbreviations that cannot be reproduced faithfully in Wiktionary because we don't have the character encodings to do so. There are Dutch maps I have with tildes over the final vowel (to represent a nasalization). There are Low German church records with the umlaut sound indicated by a small "e" as the diacritical instaed of the usual two dots. I have Hungarian and Polish documents from the medieval and Renaissance periods that use spellings and diacriticals that would make native speakers cringe because the notation isn't used anymore. If you look at Arabic, the problem gets even worse because you have calligraphers who wrote words inside of other words to make the script look pretty. We have to disentangle the individual words to represent them in a computer.
- In sum, there are just some changes that have to be made in representing words from older texts. We may not be paper, but Wiktionary does have some severe limitations when it comes to ancient languages and archaic typographies. --EncycloPetey 06:08, 30 May 2009 (UTC)
- If that's true then Wikisource is total rubbish. What are people a hundred years from now going to say about what Wikimedia contributed to the world? A thick coating of whitewash? You say you don't trust the classical texts for doing the very thing you're proposing yourself. I understand, handwriting requires interpretation just as does speech, but not using the closest approximation possible alters the text unnecessarily. Modifying the corpus is not the way to preserve a language. While I can see standardizing our entries for valid orthographical reasons such as the lacking distinction at the time, it would be entirely inconsistent to ignore distinctions such as those on your Dutch map, and an outright lie to modify quotations when they don't conform. Our standard must be to preserve the texts as closely as we can. Someone has to make the effort now, or it will be impossible to do in a hundred years, just as such information from earlier works is already forever lost. DAVilla 02:25, 31 May 2009 (UTC)
- That's why I'm giving serious thought to preparing a First Folio Romeo and Juliet for Wikisource. I've raised the issue about their Shakespeare plays in the past, but nothing has ever happened. Their currently listed Shakespeare texts don't even alert the reader to the fact that they are modernized and edited! I just have to decide whether to pursue doing Romeo and Juliet or work instead on some of the other many projects waiting for attention. --EncycloPetey 02:36, 31 May 2009 (UTC)
Presumably I've missed some kind of protracted discussion, again, but how come {{UK}} redirects to {{British}}, whereas {{US}} doesn't redirect anywhere? It just sets my teeth on edge a bit because the word ‘British’, in reference to language, sounds very, well, American. I don't see what was wrong with ‘UK’, which after all is more inclusive (and a bit shorter and neater). Ƿidsiþ 19:13, 27 May 2009 (UTC)
- I tend to agree, British has more meanings than UK does. I'd say 'British English' is as misleading as 'American English'. They do speak English in South America, albeit not at a native level. Mglovesfun 22:39, 27 May 2009 (UTC)
- On the contrary, in Guyana it is at a native level. I wonder whether Guyana's English is more similar to the UK or US standard... The uſer hight Bogorm converſation 10:05, 29 May 2009 (UTC)
- (North) American English and British English are the names of the respective dialects used by linguists and lexicographers. Dictionaries label them Amer(ican) or US, and Brit(ish) (evidence at User:Mzajac/Dialect_labels).
- The name British English has a history: until relatively recently it was the standard for “proper” writing taught in most of the British Empire and later British Commonwealth, while regionalisms were considered sub-standard. It is still the historical basis for most speech and writing, vocabulary, spelling, and usage in most Commonwealth countries (Canada being the major exception). There is no such dialect as United Kingdom English, or UK English. Today dictionaries essentially define British English as meaning “not American English.” —Michael Z. 2009-05-29 13:31 z
- I get all that, my question is not about what we call the dialect but how we label it on a definition line. If we are going to use British we should also use American. Personally I think UK and US is better. But currently we have British and US, which is just weird. Ƿidsiþ 13:41, 29 May 2009 (UTC)
- Dictionaries seem to use adjectives for countries, and attributive nouns where there is no adjective, or it would sound funny, or it's not well known, or represents a small region. Brevity is also valued, so while both American and US are used, perhaps the latter is more popular. But I would prefer Amer(ican), because it refers to American English, which is sometimes taken to mean North American. Some dictionaries use US and Canadian instead of North American. UK is not used, and is not the same as British. (We have long strings of labels on some definitions, and I think abbreviating their names with links to documentation would be an improvement, but that is another topic.) See User:Mzajac/Dialect_labels#The_form_of_dialect_labels for a list of labels actually used. What does your dictionary or dictionaries use for American and British English?
- And certainly Category:US looks like a mistake among the members of Category:Regional English. —Michael Z. 2009-05-30 02:04 z
- If you say so, personally I don't think that putting UK means that we are suggesting there is a dalect called ‘UK English’ (not that that sounds particularly wrong). We still use US but I would still always think of ‘American English’ as being the dialect name. In short, UK and US are fairly obvious shorthand ways of referring to ‘British English’ and ‘American English’ which have the advantage of brevity and also of being, in my opinion, less patronising. Ƿidsiþ 06:39, 30 May 2009 (UTC)
- But “UK English” is practically a made-up name for British English, almost unattested in language writing. Its invocation of political boundaries is both over and under-specific, implying that there is some commonality in the English of England, Scotland, and Northern Ireland (but not in that of the Republic of Ireland). British English is associated historically and linguistically, by its source and scope of usage, with England, Britain, and the British Empire and British Commonwealth. UK English is a neologism lacking these connotations. —Michael Z. 2009-05-30 16:49 z
- I finally understand your position, now. To be perfectly honest, I never took “British English” to include the English of Australia and New Zealand — UK & Commonwealth is the label for that referent. Also, even if we were to take
{{British}}to mean the English(es) spoken in most of the quarter of the globe that used to belong to Britain, how would we then label usages that are restricted to the UK only? † ﴾(u):Raifʻhār (t):Doremítzwr﴿ 17:35, 30 May 2009 (UTC)
- I finally understand your position, now. To be perfectly honest, I never took “British English” to include the English of Australia and New Zealand — UK & Commonwealth is the label for that referent. Also, even if we were to take
- [It took me a while to get the picture of why this term appeared to be used with such variety too]
- Well, that's part of the thing, there isn't a dialect or language variety of the UK. English in the UK and British Isles is represented by several national varieties—English and Welsh, Scottish, and Irish—and their regional subdivisions. There are terms for things which are specifically in the UK, for example SAS (1). But the SAS is called SAS in Canada and the USA too, so it's wrong to mark that sense as belonging to British English—“in the UK” in this case is a national topic, not a regional dialect (the only dictionaries to consistently label this phenomenon is the COD and its descendants, like the CanOD). Another example is Category:England and Wales law, which stems from the scope of a court system, not a language variety. —Michael Z. 2009-05-30 21:19 z
- Firstly, I've already said I have no position on what to call the dialect and this is just about labelling a definition line. We currently use US to tag definitions but most people still call the dialect ‘American English’. Secondly, ‘UK’ is not exclusive of Northern Ireland, quite the contrary, it is ‘Great Britain’ which is strictly just the mainland. Thirdly, as per Raif‘har above, no one is likely to interpret ‘Britsh’ as referring also to Commonwealth English. Ƿidsiþ 06:15, 1 June 2009 (UTC)
- It seems to me that you're suggesting we call the dialect “UK” for short. But no one calls it that. The standard abbreviation is Brit.
- (I don't see what bearing the rest has on this. Firstly, US is used to label American English terms in dictionaries, UK is not used for British English. Secondly, I certainly wrote above that the UK includes Northern Ireland but not the Republic of Ireland, rather than following any dialectal boundaries. Thirdly, why would anyone better interpret a label that no dictionary uses, rather than the label that practically all dictionaries use?—is “UK & Commonwealth” found in any dictionary at all?) —Michael Z. 2009-06-02 01:11 z
- Yup: the OED uses “US” and “Brit” in its entries; nevertheless, that is really bad nomenclature — it doesn’t matter if that’s the lexicographical convention, because it’s so unintuitive and misleading, our users will assume that “Brit(ish)” just means the English of Britain and it will not occur to them that they might have misinterpreted the scope of the label. Let’s use
{{UK|and|Commonwealth}}, if anything, please. † ﴾(u):Raifʻhār (t):Doremítzwr﴿ 20:46, 3 June 2009 (UTC)
- Yup: the OED uses “US” and “Brit” in its entries; nevertheless, that is really bad nomenclature — it doesn’t matter if that’s the lexicographical convention, because it’s so unintuitive and misleading, our users will assume that “Brit(ish)” just means the English of Britain and it will not occur to them that they might have misinterpreted the scope of the label. Let’s use
- (Incidentally, according to Norri 1996,[3] the OED only uses labels to indicate “the variety of English, when the word is not current in the standard English of Great Britain”—so British is its default. Almost all other British and American dictionaries use British in the conventional sense.)
- So you propose to mark other dictionaries' British with UK|and|Commonwealth, and presumably to replace our UK/British with the same. So then exactly what is signified by just UK or just Commonwealth? Since these would be new distinctions, used by no other source, what references would we base our assessment on? If an editor finds a term marked British in several other dictionaries would he be wrong to mark it just UK or just Commonwealth? —Michael Z. 2009-06-04 04:21 z
- Nope—that would just be wrong. Whatever definitions you see, British English is an international standard language—its name relates to Britain and the British Empire, and its nature is as much register as it is regional. British English may include RP and BBC English, and historically, and perhaps still, is the basis for much of the formal written and spoken language of Scotland, Ireland, India, Australia, etc. One might consider calling it Standard English, if there weren't already another important standard of American English.
- British English is the name for it. Just because you don't like the sound of that, or you don't think it neatly corresponds to the borders of countries, gives you no right to reject universal lexicographical practice. Turning it into three (!) arbitrary dialectal subdivisions UK, Commonwealth, and UK and Commonwealth for the sake of more pleasing naming doesn't even deserve to be dignified as original research. —Michael Z. 2009-06-05 18:35 z
Patroller's flag
Hi. Could you add at the patroller's flag the rights autopatrol & rollback? Thanks --Ivocamp96 13:27, 28 May 2009 (UTC)
- Hi, you already have the autopatrol right (it's allotted by the sysops at WT:WL when a user is editing well). We don't give out rollback or patrol as you'll get them when you become a sysop. (The last thread that discussed this seemed of the general conclusion that if you were good enough to be allowed to patrol, you were good enough to be an admin anyway). Conrad.Irwin 14:46, 28 May 2009 (UTC)
Word of the Day
Hi. There is no Word of the Day for today, May 28.
- It should come up as unsung. Take a look at the WOTD archive and try refreshing you screen, and if it's still not there let us know what you do see. DAVilla 17:40, 28 May 2009 (UTC)
L2 header Serbo-Croatian instead of Croatian, Bosnian, etc.
- note that the heading for this section was improperly altered from the original
(I tripped over this yesterday when starting Tbot on a new run; the first thing it did was add a new section for Croatian to the entry at rječnik; this surprised me as I would have thought it surely was there already! (rječnik is "dictionary" ;-) on investigation I found this very disturbing edit.)
At least one person (perhaps more, I have only started to look into this) has apparently taken some recent discussion of the "Serbo-Croatian" language group as licence to remove the valid, recognized languages (Croatian and Bosnian, and in some cases Serbian itself) from entries, replacing them with the invalid "language" "Serbo-Croation". Note that that is not a language recognized by SIL/ISO, and therefore does not meet CFI, the code ("sh") was properly deleted by SIL/ISO. (Serbian itself is "sr", alive and well ;-)
Given who has been doing this (that I have seen so far), I will respectfully ask that you undo the severe damage caused by the removal of the CFI-valid languages, in all entries thus far damaged. (If it was anyone else, it would have of course been instantly reverted and the user(s) permanently block/banned.) Robert Ullmann 09:16, 30 May 2009 (UTC)
- I don't know, and cannot formulate any plausible theory of, what might have happened after this discussion (among others) and before this one (among others). However, given that said thing(s) happened, I think any further discussion should join the existing discussion at Wiktionary talk:About Serbo-Croatian. —RuakhTALK 13:10, 30 May 2009 (UTC)
- L2 Bosnian, Croatian and Serbian are to be obsoleted and replaced by L2 Serbo-Croatian, and the details are still being worked out at the abovementioned policy draft page that is to be voted on some time in the near future (when technical details such as this one get sorted out, and when my Latin->Cyrillic transformation tool for SC entries becomes 100% operative). SIL doesn't really decide what is a "language" or not (we already have Wiktionary:Languages without ISO codes, remember..), and the macrolanguage terminology they use for SC (and many of other L2s the Wiktionary already uses, see the full listing [4]) is non-existent in general linguistics. It is much easier to escape unnecessary redundancy of having 2-3 separate but identical sections for 99% of SC words (words that are exclusive to either of the triad are really rare), and have only one instead. Also, sh code is safe to use as ISO doesn't assign two-letter codes anymore AFAIK. I've disabled the generation of Tbot entries for Croatian for now. --Ivan Štambuk 13:50, 30 May 2009 (UTC)
- How have you "disabled ... Tbot entries"? I don't know of any such mechanism? Robert Ullmann 15:46, 23 June 2009 (UTC)
- I've set the limit= parameter to 0 [5]. --Ivan Štambuk 16:20, 23 June 2009 (UTC)
- That hasn't been used since Decemeber 2007. Robert Ullmann 06:59, 24 June 2009 (UTC)
- OK, could you please set the killbit on the creation of bs/hr/sr entries? :) --Ivan Štambuk 08:19, 24 June 2009 (UTC)
- That hasn't been used since Decemeber 2007. Robert Ullmann 06:59, 24 June 2009 (UTC)
- I've set the limit= parameter to 0 [5]. --Ivan Štambuk 16:20, 23 June 2009 (UTC)
- How have you "disabled ... Tbot entries"? I don't know of any such mechanism? Robert Ullmann 15:46, 23 June 2009 (UTC)
This is totally unacceptable. ISO/SIL very properly deleted the code "sh" because it is both bogus and offensive. The languages are Bosnian, Croatian, and Serbian, all properly defined and coded.
Several people have begun severely damaging entries by "combining" the languages; it must stop and be un-done. "Serbo-Croation" is not a language, by international standards. Full stop.
If it continues we will have to call for community censure of the people pushing this offensive Serbian-nationalist POV. Robert Ullmann 15:43, 23 June 2009 (UTC)
- As I said, ISO/SIL don't define what a "language" is. It wasn't "bogus and offensive" 20 years ago and now suddenly is? Hardly, except in the minds of some insane nationalists. It's the most practical term to use unless we want to stray into needless political correctness with terms such as "BCS". The introduction of new 3/4 codes by ISO merely reflects the separate standardization bodies used for B/C/S(/M) nowadays. There are lots of languages which still don't have ISO code and rightfully deserve one, and there are even some languages that have ISO code but hardly deserve one (e.g. the so-called "Knaanic language", imaginary Slavic language no one's ever heard of).
- I don't see how combining in most cases identical 3 language sections into one is damaging in any kind. It reduces needless redundancy and makes it easy for both the users (learners) and maintainers (editors). Most (up to 15 years ago - all) English-language textbooks and courses treat it as one language, with one combining dictionary, grammar...accompanied with commentaries on regional differences in lexis (the grammar is 99% the same). That's the best way to pursue on Wiktionary IMHO. --Ivan Štambuk 16:20, 23 June 2009 (UTC)
- For the record, I support this unification here on the grounds of usefulness and scholarly opinion, which have been explained amply by Ivan. I cannot see how this can be harmful; this is really only a technical matter. Also, I must say that it's very prejudiced of Robert to assume that "offensive Serbian-nationalist POV" is being pushed here; nationalism (on the level of Bosnian/Croat/Serb/Montenegrin) is the very barrier a unified header breaks, and, as Robert may perhaps not realize, although there was a time when attempts were made to impose elements common to speech in Serbia (such as ekavianism), the modern literary Serbo-Croatian (or whatever you'd like to call it) as it has been used in the old Yugoslavia and in later times, although always colored (as in any other language) by the writer's particular dialect, owes a huge part of its development to historical Croat writers as well as Serbs (Croatian vernacular literature being older). Also, Ivan could hardly be considered a "Serbian nationalist", as he is a Croat. – Krun 17:12, 23 June 2009 (UTC)
- I also want to note that the main dialectal differences are in practice not just drawn on ethnic (Serb/Croat) lines, as some people would like to think. Bosnian Serbs (i.e. ethnic Serbs living in Bosnia and Herzegovina), for example, predominantly speak an ijekavian vernacular, but still want to relate more to Serbian Serbians in language naming. In reality, this is one dialect continuum with the language standards, despite nominally affirming their separateness, that are almost identical. Even this yat-reflex issue is just minor and silly to reflect in spelling; it would be easy to instead just use ѣ, or ě in Latin script, that would then be pronounced slightly differently by different speakers; that would probably get rid of most of the existing spelling variations and simplify things greatly for everyone. Of course, we can't go as far as to set a new spelling standard, but as the spelling is, in Ivan's system it's very easy and straightforward to create pages for the yat-reflex variants, and they are shown for what they are (i.e. not necessarily specifically Serbian, Croatian, etc., but used in various regions in Serbia, Croatia and Bosnia and Herzegovina). – Krun 19:40, 23 June 2009 (UTC)
- For the record, I support this unification here on the grounds of usefulness and scholarly opinion, which have been explained amply by Ivan. I cannot see how this can be harmful; this is really only a technical matter. Also, I must say that it's very prejudiced of Robert to assume that "offensive Serbian-nationalist POV" is being pushed here; nationalism (on the level of Bosnian/Croat/Serb/Montenegrin) is the very barrier a unified header breaks, and, as Robert may perhaps not realize, although there was a time when attempts were made to impose elements common to speech in Serbia (such as ekavianism), the modern literary Serbo-Croatian (or whatever you'd like to call it) as it has been used in the old Yugoslavia and in later times, although always colored (as in any other language) by the writer's particular dialect, owes a huge part of its development to historical Croat writers as well as Serbs (Croatian vernacular literature being older). Also, Ivan could hardly be considered a "Serbian nationalist", as he is a Croat. – Krun 17:12, 23 June 2009 (UTC)
- That's all correct. Originally Karadžić's Serbian was ijekavian of his native Hercegovina, which was spoken by few Croats, but once his reform was officially accepted in 1868 they switched to ekavian variety which was prevalent in the mainland Serbia, and by that time ijekavian pronunciation became very spread in Croatia (chiefly due to the efforts of Croatian Vukovians like Maretić, Broz etc.), and by the twist of history the positions changed. Anyhow, It is indeed very unfortunate that the spelling with jat reflexes is not indicated with <ě> - in the 19th century during the Illyrian movement one philological school advocated exactly that, so that all speakers would write <ě> and pronounce /i/, /e/, /ie/ /æ/ or whatever their regional pronunciation was. You can see that spelling used in some 19th century magazines like Danica Ilriska. Unfortunately, strict phonological spelling eventually prevailed and so we're stuck with 2 script x 2-3 jat varieties of basically one and the same word.
- What is important to understand here that Wiktionary is using scheme whose primary purpose is to enhance learning process, i.e. that person using Wiktionary to learn SC words doesn't end up wasting time chasing 3 or 4 language sections to discover variant spellings, depending on which ethnicity uses which jat reflex. Similarly, variants in lexis and morphology are all being reflected in ==Usage notes==. It is much easier to note in one entry that e.g. Croatian uses doktorica whilst literary Bosnian and Serbian prefer doktorka, and mutually link between those two, than create 3 entries on 2 different pages and let the poor reader figure it out on his own. This is not some kind of political agenda to "unify" languages - they're all 3 different standard based on 1 organic idiom (stylised Neoštokavian dialect). This is just a convention to ease the efforts of both editors and users. We already use the same thing for Hindi and Urdu (Hindustani, written in Devanagari and Arabic script respectively) and the Romanian and Moldovan (using the Latin and Cyrillic scrip respectively). It's just that with SC we have the luxury of using the same L2 section name, that has (had) it's own ISO code. --Ivan Štambuk 20:27, 23 June 2009 (UTC)
- To Robert Ullmann: Since you, on my user talk page, purport to know the criteria for inclusion so well you should have at least paid attention to what they actually say. They do not, as you seem to believe, stipulate that only languages with a current ISO 639-3 (or other ISO) code may be included. In fact, ISO 639-3 seems only to be mentioned for its inclusion of several constructed languages, which have been considered, and most of them accepted, here. That could be taken, at most, to indicate that we should consider including the languages included in the standard, but further down reasons (agreed upon by consensus) are stated for not including a few of the languages which are in the standard. It says nothing whatsoever about not including other languages; on the contrary, it states that "All natural languages are acceptable." It does not, however, state specifically what we consider a language, nor does it refer the matter to SIL's judgement. Here is a list of the numerous languages not in the standard that we are already including (and have created code extensions for many of them): Wiktionary:Languages without ISO codes. So, you see, Serbo-Croatian isn't the only one. There should of course be discussion on each case (as is now going on), but you don't have to come out of the blue and attack with prejudice and ignorance honest attempts at making a better Wiktionary. In particular, the so called "damage" you mention is nonexistant. It would be very simple to have a bot split the sh entries (in effect, simply tripling the vast majority of them), and that is precicely the point. We could simply vote on this (preferably when a few more users have contributed to the conversation, of course); to be honest, I am quite confident that this will pass through. It would be quite nice to see this matter finally settled. – Krun 23:11, 23 June 2009 (UTC)
- Oh dear, another Balkan war. Will those people ever learn anything? Jcwf 00:35, 24 June 2009 (UTC)
- The lesson from 1990s war was: never trust Dutch "peace-keeping" soldiers who shit their pants and hand 8000 unarmed civillians that are about to be slaughtered in the biggest genocide in Europe since WW2, and later come and preach of "war crimes" and "justice". --Ivan Štambuk 01:24, 24 June 2009 (UTC)
Just thought I’d censor some personal attacks. Cut it out, guys. I couldn’t give a flying fuck about whichever brand of Balkan nationalism one party or another is trying to POV-push. With that in mind, please note that, FWIW, I tend to find that the stronger case has been made thus far by those who seek to unify under a single language header our presentation of the Serbo-Croatian language (insert or omit as appropriate: continuum). † ﴾(u):Raifʻhār (t):Doremítzwr﴿ 02:23, 24 June 2009 (UTC)
Let's vote on this and decide once and for all. The vote should not suggest whether these are separate languages or dialects, which cannot be decided by vote of course, but to propose a standard of treating Serbian/Croatian/Bosnian/Montenegrin on Wiktionary. For the record, I would vote for unifying. --Vahagn Petrosyan 06:41, 24 June 2009 (UTC)
This is not susceptible to a "vote". Given the history of the genocide committed by Serbians attempting to maintain a "greater Serbia" by massacring Bosnians and Croations, (and trying to exterminate the Albanian Kosovars), an attempt to remove Bosnian, Croatian (and Montenegrin) by "combining" them into a greater Serbian language is utterly beyond obscene. (With trials ongoing; Damir Sireta was sentenced by the Tribunal just yesterday.)
It would not be more offensive if someone put a swastika on their user page and went around deleting Hebrew from entries.
Suppressing Bosnian and Croatian cannot not be accepted. Robert Ullmann 06:55, 24 June 2009 (UTC)
- You should also note this (for example). Linguistic genocide, of exactly the sort being contemplated here, was considered as a possible part of the 1948 Convention. I'm not saying we shouldn't do "Serbo-Croation" solely because it somehow reflects the Serbian war crimes (albeit that is sufficient). I am saying that that is an act of linguistic genocide, in itself a war crime. We can't "vote" on whether or not the Wiktionary (and therefore the Wikimedia Foundation) will commit a war crime! Robert Ullmann 07:14, 24 June 2009 (UTC)
- Really Robert, can we all dispense with the bullshit emotional rhetoric? Whilst I don’t really want to try to crack that old chestnut, viz. “What is a language?”, it seems pretty clear to me that, just going on arguments of functionality, treating Serbo-Croatian as a single language with regional differences is a lot better than triplicating most of its lexis, whilst the few non-universal national differences are obscured thereby. Seriously, if we distinguish Serbo-Croatian as separate languages for each of the countries that speak it, then for consistency, we should probably split English into US English and UK English, at least; heck, who cares if we duplicate our content? –After all, we all remember this ugly little episode, and those two languages each have an army and a navy…
- As you might have guessed, I am dead against making our decisions on any grounds other than linguistic and functional ones. Still, if we want to imply argumenta ad hominem and play victim politics, you should nota bene, as has been said more than once, that Ivan Štambuk is a Croat. How odd that a person whose people has been, as you assert, historically shit-kicked by the Serbians should choose to subsume his own special, unique linguistic identity under the Serbian yoke! How nice it is to see that at least someone has managed to “receive ‘disinfection’ from nationalism disease”… † ﴾(u):Raifʻhār (t):Doremítzwr﴿ 10:25, 24 June 2009 (UTC)
- I can't read that page, what's it saying? During the Yugoslavia 1945-90 there was indeed lots of "Serbification" of the Croatian literary standard (mostly resulting from a dumb attempt by Communist authorities to suppress Croatian purism efforts which reached its peak in the 1941-45 Nazi puppet state which officially banned all "Serbianisms", coined a bulk of neologisms and introduced a new orthography, thus in the post-war era creating a subconscious connection with purism and NDH/Ustaše regime - which is all silly as purist efforts predate it for centuries, and it on the whole moreover fueled additional Croat nationalism and anti-Serb sentiments which eventually lead to the destruction of Yugoslavia..). However, the concept of unified Serbo-Croatian language predates the Creation of 1945 Yugoslavia - from the early 19th century writers sought to create common literary language (see e.g. w:Vienna Literary Agreement - in 1850), and this all actually happened at the beginning of the 20th century, and what was being done in 1945+ was just really trivial details being resolved. Your analogy with swastikas, war crimes etc. is really inappropriate, because Serbo-Croatian is still very much used term on the West, and is treated like single language in publications (although often under the name "BCS" or similar unnecessarily politically-correct coinage). E.g. Britannica still uses the term [6] (and searching on individual varieties redirects to the page on SC), as well as do most of the expert on the subject (e.g. Wayles Browne who wrote the chapter on SC] in the standard reference monography Slavonic languages by Comrie & Corbett), not to mention etymological dictionaries (Vasmer-Trubačev, Derksen, Skok..) and current research papers which all still use the Serbo-Croatian terminology. So there is no point to trying to demonize the term with such absurd comparisons as obviously the term is still very much in use. --Ivan Štambuk 08:19, 24 June 2009 (UTC)
I think that we should clearly accept all of following languages:
- Serbo-Croatian, because there is a Wikipedia using sh (Serbo-Croatian) as its code
- Serbian, Croatian, etc. because ISO codes exist for these languages.
This may seem strange, but these reasons seem good enough, and objective, and this would allow everybody to participate, whatever their linguistic opinions. Otherwise, the discussion will never end. Lmaltier 07:29, 24 June 2009 (UTC)
- Wow, wouldn't that be great! Adding Serbo-Croatian? No, no, no. We can't be having both systems, as that would be inconsistent and self-contradictory. We have to decide on either separateness or unification. And, Robert, you seem to be finding it hard to comprehend all of this. Let me clarify: This is not a proposal to include only the Serbian standard under the guise of Serbo-Croatian. Anything that is specific to a particular region will be marked as such (including terms limited to Serbia), with links to synonyms that are preferred in other regions. There is no intention of "suppressing Croatian and Bosnian". Weren't you paying attention to what I pointed out previously, anyway? Ivan Štambuk is a Croat. If he came across a term that is not used in Croatia he would of course mark it appropriately and provide a link to the term prevalent in Croatia, as any knowledgeable user would. The nomenclature is another matter, and is of course debatable, but as Ivan has also said, the term "Serbo-Croatian" has a lot of currency in scholarly circles in the region and elsewhere (both historically and today) compared to other unification terms that are being used for the language. We can of course also try to be more "politically correct" with the naming, whatever that really means. To answer Ruakh's question above, this BP conversation might clarify Ivan's change of heart. – Krun 09:50, 24 June 2009 (UTC)
- Actually, I don't propose to add anything, what I propose is to make current practice official (and it's current practice on fr.wiktionary too). It's not inconsistent nor self-contradictory, only redundant. The principle is don't remove sections with these headers, even when redundant. I'm not surprised by your reaction, but I cannot imagine another consensual solution. Lmaltier 10:06, 24 June 2009 (UTC)
- Neither of the regular SC contributors around here (me, Dijan, Bogorm, and recently Krun) is willing to maintain 4 (soon 5 - Montengerin is coming to be formally codified this autumn, and prob. granted ISO code) entries per one word in what is doubtless one and the same language. It would be a waste of time and space. Those who disagree with the unification AFAICS base their arguments on political prejudice and ignorance, and are likely to be outvoted if the issue is to be resolved by a vote. I still hope that everyone will come to their senses. --Ivan Štambuk 10:24, 24 June 2009 (UTC)
- But I don't propose that you maintain 4 or 5 entries in the same page, I only propose that, if somebody creates them, you don't remove them. If you create only Serbo-Croatian entries, then there will be mainly Serbo-Croatian entries here. But Croatian, etc. entries should also be accepted, if other contributors want to create them, and I propose that they don't remove Serbo-Croatian entries either. Actually, I think that all languages with an ISO code or a Wikipedia code should be accepted, without exception (+ other languages only after discussion). Lmaltier 11:05, 24 June 2009 (UTC)
- But I don't propose that you maintain 4 or 5 entries in the same page, I only propose that, if somebody creates them, you don't remove them. - Sorry but this makes no sense to me. It would be a complete waste of time and space, and for what purpose? That some rabid nationalist doesn't feel "offended" seeing ==Serbo-Croatian== and not their own L2 imaginary language name? Completely silly, as 99% of English speakers who'd be presumably looking up SC words on Wiktionary have no such prejudice. Do you on the fr.wikt have actual SC editors that contribute and maintain such duplicate entries in 4(/5) separate sections, or all of your SC entries are bot-generated from translation tables? --Ivan Štambuk 11:36, 24 June 2009 (UTC)
- On fr.wiktionary, some Serbo-Croatian entries were created by contributors speaking it (e.g. Bogorm), and most from translations tables, you are right (but manually, not by a bot). I don't promote redundancy, I just propose to accept it. Serbian, etc. are not imaginary language names. If you want to find a consensus, please consider the proposal a bit more. There are Wikipedias in Serbo-Croatian, in Serbian, in Croatian... despite the probable partial redundancy. The Foundation accepts this redundancy, but I don't think they would tolerate the exclusion of Serbian or Croatian from the list of allowed languages. Why not asking them? Lmaltier 12:37, 24 June 2009 (UTC)
- Lmaltier’s proposal sounds like the most practical ATM. Let’s have Serbo-Croatian worked on properly, whilst all the separate languages just falter by neglect. Pointless but harmless. † ﴾(u):Raifʻhār (t):Doremítzwr﴿ 12:48, 24 June 2009 (UTC)
- I cannot comprehend what is "practical" in quadrupling the content. Will you or Lmaltier be erasing that redundant shite later? I don't think so. I've been converting all of Croatian entries to SC for some time I have no plans to cease that activity unless someone comes up with an argument that doesn't include swastikas, hurt feelings and similar. Preferably from someone who actually knows the language. --Ivan Štambuk 13:24, 24 June 2009 (UTC)
- Lmaltier’s proposal sounds like the most practical ATM. Let’s have Serbo-Croatian worked on properly, whilst all the separate languages just falter by neglect. Pointless but harmless. † ﴾(u):Raifʻhār (t):Doremítzwr﴿ 12:48, 24 June 2009 (UTC)
- So the only native-speaker contributor of SC you had was creating them under ==Serbo-Croatian==. Interesting. I think that Bogorm would agree that having simultaneously 4(/5) language sections would look ridiculous, and is not an reasonable option.
- I don't promote redundancy, I just propose to accept it. - This sentence doesn't make any sense. You are indeed by accepting the redundancy promoting it. I'm not sure you understand what you're saying: Every single SC entry is to be quadrupled for the sake of what? Some insane political correctness, that is not even practiced in lots of English scholarly literature (I cited authors, dictionaries, grammars, renowned encyclopedias and reference works etc.)
- There are indeed Wikipedias in bs/hr/sr/sh - what you may now that there was initially only Wikipdeia in sh, and subsequently 3 new ones were created (there was also unsuccessful proposal for Montenegrin), and these 4 mutually copy/paste great deal of content. The only reason why someone contributes to hr and not bs/sh Wikipedia goes along ethnic lines, nothing else. From the perspective of dialectology and genetic linguistics, it is one language - Neoštokavian dialect, aka SC, in 4 nationally codified variants with 99% identical grammar, 100% mutual intelligibility (e.g. Serbian and Bosnian TV shows are given on Croatian national television without subtitles) and minor differences in lexis resulting from different cultural affiliation throughout the history. As I said before, it's exactly the same thing that we already have and do for Hindi/Urdu and Romanian/Moldovan, with the luxury of having a well-used common name and ISO code to bind them under the same umbrella.
- If by "them" you mean contributors of bs/hr/sr wikipedias - I assure you you're wasting your time as all you'll get is some brain-damaged non sequiturs, long "historical perspective" type of prosaic "arguments" ridden with inaccuracies, logical fallacies and insane PoV. --Ivan Štambuk 13:11, 24 June 2009 (UTC)
- No, by them, I mean the Foundation (those who buy servers...) Why not asking the Foundation what decisions they would be willing to accept, to save time? Lmaltier 13:35, 24 June 2009 (UTC)
- The decisions are not for them to accept as the Foundation does not own the content that it stored on their servers, and can in no way impose or work against the community consensus. (I still hope that one day Wiktionary database will migrate out of this horrid PHP environment.) If you want to, feel free to ask the so-called Language committee for a comment, whether the creation of bs/hr/sr wikiprojects had anything to do with languages, as opposed to the self-perceived notion of ethnicity, and how these "different languages" came to exist in the first place. I'm sure you won't hear any technical details on why this unification scheme wouldn't work. Esp. pay attention to one of the members, Millosh, who appears to be a native speaker himself. If you had someone else in mind, feel free to ask them too. --Ivan Štambuk 14:36, 24 June 2009 (UTC)
- They don't own contents, but they may close projects when their basic requirements are not met (especially neutrality and copyright requirements). It would not be the first time. But, of course, it won't happen, and I'm confident that a good decision will be taken. I don't intend to ask them personally, it was a suggestion to people who know them. Lmaltier 14:54, 24 June 2009 (UTC)
- No, by them, I mean the Foundation (those who buy servers...) Why not asking the Foundation what decisions they would be willing to accept, to save time? Lmaltier 13:35, 24 June 2009 (UTC)
- Lmaltier's proposal to allow for Bosnian, Croatian, and Serbian as well as for Serbo-Croatian looks workable. The above discussion and some previous discussions show there is a lot of heat in the issue on both sides, at the expense of strict logic. Lmaltier's proposal allows to leave the issue open, so that at some later point both of the contesting options can be considered for what they have become, not for what they are, before the act, thought or speculated to become. After, in the future, there is a consensus about keeping only Serbo-Croatian, erasing Bosnian, Croatian, Serbian sections should be easily done using a robot. On style, I think that strong terms such as "insane" and "shite" add oil to the heated discussion while bringing nothing to the substance of argument. --Dan Polansky 15:22, 24 June 2009 (UTC)
- Well I've been holding back enough and my patience left for folks who are full of "solutions" for this "issue", but whose knowledge and contributions to the field of SC entries are infinitesimal, is increasingly growing thinner. All of the current Wiktionary SC contributors support the unification. Those who see problems with the WT:ASC policy may raise their real arguments on its respective talk page, whose creation was announced few months ago in BP, or otherwise kindly shut up. Quadrupling entries is simply brain-damaged and cannot pass. --Ivan Štambuk 16:21, 24 June 2009 (UTC)
- Ivan, "shut up" and "brain-damaged" do not count as arguments, not in my universe anyway. I have contributed zero to the Bosnian, Croatian and Serbian entries. I find the argumentation style of yours and other supporters of the Serbo-Croatian option aggresive and overconfident, not something I would like to interefere with, lest I earn some nice names in this public forum. --Dan Polansky 16:32, 24 June 2009 (UTC)
- They were not intended to be arguments of any kind. The suggestion of quadruplication of entries is brain-damaged whether I say it or not. For Christ name, _who_ exactly is going to benefit from 4 identical L2 sections? Some nationalist feelings won't get hurt? (they'll more likely to laugh their ass out seeing such a mess). Ullmann's arguments are a futile crusade based on prejudice and misconception. We all know how the Norwegian Nynorsk/Bokmal issue ended up, him vs. the rest of planet... This is exactly the same thing. If Ullmann, Lmaltier, Wren, Foundation, you or anyone else of "experts" have anything specific to object to the proposed policy, I advise you to take it to its talkpage. If you have any coherent questions to ask, fell free to state them and they'll be answered. Otherwise we're all just wasting time. --Ivan Štambuk 17:15, 24 June 2009 (UTC)
- Ivan, "shut up" and "brain-damaged" do not count as arguments, not in my universe anyway. I have contributed zero to the Bosnian, Croatian and Serbian entries. I find the argumentation style of yours and other supporters of the Serbo-Croatian option aggresive and overconfident, not something I would like to interefere with, lest I earn some nice names in this public forum. --Dan Polansky 16:32, 24 June 2009 (UTC)
- Well I've been holding back enough and my patience left for folks who are full of "solutions" for this "issue", but whose knowledge and contributions to the field of SC entries are infinitesimal, is increasingly growing thinner. All of the current Wiktionary SC contributors support the unification. Those who see problems with the WT:ASC policy may raise their real arguments on its respective talk page, whose creation was announced few months ago in BP, or otherwise kindly shut up. Quadrupling entries is simply brain-damaged and cannot pass. --Ivan Štambuk 16:21, 24 June 2009 (UTC)
- I do not like Lmaltier's method (nothing personal). Having both a language (or language family) and several dialects thereof (or languages therein) is a Bad Thing™. That said, I do not know anything about this language (or these languages), so cannot weigh in on one side or the other (and see nothing wrong with one method or the other).—msh210℠ 17:19, 24 June 2009 (UTC)
- Lmaltier's method seems to me to be more in the spirit of a Wiki, despite the clear language-learning and maintenance benefits of Ivan's proposal. Are there ways that we can achieve at least some of the benefits Ivan seeks without violating "Wiki spirit"?
- I wonder whether contributors of entries under Croatian, Serbian et al couldn't correct entries' erroneous L2 headers. The determination of when that would not be in violation of "Wikispirit" might be: when no edit to the section was made by anyone not explicitly consenting to such changes on any entry they had edited. If the active contributors in this area consented, I would expect that many entries could be corrected in this way (and all the associated translations). I have no idea as to the feasibility of automating the process, which I'm sure is the plan.— This unsigned comment was added by DCDuring (talk • contribs) at 18:43, 24 June 2009.
- I fail to understand how exactly the current WT:ASC proposal is "against Wikispirit". You do exactly the same thing as you did before, just using ==Serbo-Croatian== and code sh instead of whatever you used before. You don't even have to put alternative spelling in Roman/Cyrillic, or regional labels - you can e.g. just tag the entry with
{{attention|sh}}and someone knowlegeable will come along. - As for the conversion of entries - I've (and others) been doing it manually, cleaning up and expanding in the process. And this has started more than 2 months ago. There are no problems except with folks with no knowledge on the subject and no contributions to SC entries. Is someone is offended by seing his beloved ==B/C/S== replaced by ==Serbo-Croatian== he should probably pay a visit to psychiatrist and come back when (and if) he's been cured. --Ivan Štambuk 19:15, 24 June 2009 (UTC)
- Your own user page mentions both hr and sh. I only propose to accept this kind of thing. Lmaltier 19:31, 24 June 2009 (UTC)
- That has absolutely nothing to do with this issue. I see the hr babelbox as "I am a native speaker of Croatian variety of Serbo-Croatian". You can find similar babelboxen with other editors for e.g. American/Brittish English, and for a number of other more-precise indicators of regional variant the user has native proficiency in. --Ivan Štambuk 21:02, 24 June 2009 (UTC)
- Your own user page mentions both hr and sh. I only propose to accept this kind of thing. Lmaltier 19:31, 24 June 2009 (UTC)
- I fail to understand how exactly the current WT:ASC proposal is "against Wikispirit". You do exactly the same thing as you did before, just using ==Serbo-Croatian== and code sh instead of whatever you used before. You don't even have to put alternative spelling in Roman/Cyrillic, or regional labels - you can e.g. just tag the entry with
- The aspect of "Wikispirit" is that no one simply trashes someone else's contributions unilaterally and en masse. Of course, all contributions are under GFDL so no contributor "own" the entry in whole or in part. The idea would be to reduce the likelihood of any edit wars on an entries by selecting entries that are less likely to be on the watchlist of anyone who might object. I sometimes feel entitled to make massive corrections to my contributions if there have been no subsequent changes by others, but usually feel constrained to use TR/RfC/RfV/RfD if other editors have gotten involved subsequently. If you need some kind of sanction from the community to complete your efforts, then it might be necessary to consider community values. I can only speak as an individual, but I have inferred or imagined this "WikiSpirit" based on the best of the times I have spent here.
- As to the mental health of contributors, how can any of us question other people's mental health without questioning our own based on the simple facts of our colossal, unrecompensed labors ? DCDuring TALK 19:50, 24 June 2009 (UTC)
- Do you see any edit wars around here? I saw only one - [7], Ullmann's undoing of "severe damage" by triplicating the information. Let me repeat again and again: all the regular SC contributors, responsible for the creation of 99.9% of SC entries, agree on the unification. All the opposing arguments that were given by others here and elsewhere are based on irrational prejudices, utter ignorance and silly political correctness, do not invalidate the enormous benefits of the merging proposal in any way, and cannot be held as sound. --Ivan Štambuk 21:02, 24 June 2009 (UTC)
- I've not been doing patrol duty lately so I don't know whether there are any. If all of those agreeing indicate that they will not change (on pain of ?) any Serbian, Croatian or ? language section that has had a contribution from any other user (including anons), that would satisfy me and my Wikispirit. I can't speak for others and their Wikispirits. Could you clarify whether I am being irrational, ignorant, silly, or merely unsound on this? DCDuring TALK 21:46, 24 June 2009 (UTC)
- Do you see any edit wars around here? I saw only one - [7], Ullmann's undoing of "severe damage" by triplicating the information. Let me repeat again and again: all the regular SC contributors, responsible for the creation of 99.9% of SC entries, agree on the unification. All the opposing arguments that were given by others here and elsewhere are based on irrational prejudices, utter ignorance and silly political correctness, do not invalidate the enormous benefits of the merging proposal in any way, and cannot be held as sound. --Ivan Štambuk 21:02, 24 June 2009 (UTC)
AEL
(reset) I have no problem bringing separateness/unification up for a vote, and would probably side with the linguistic arguments of the active contributors. I would not support the added redundancy of allowing both unified and separated headers. --Bequw → ¢ • τ 23:04, 24 June 2009 (UTC)
- I was asked about my opinion on this. When I was a Russian student at the military Defense Language Institute, some of my friends were studying Serbo-Croatian. Besides the Russian that was my MOS, I listened to a lot of Serbo-Croatian from my positions along the Iron Curtain. I know, as I have always known, that Serbo-Croatian is a single language. What happened upon the breakup of Yugoslavia was the result of smoldering hatred based along mostly religious lines and political leanings. The dialects of Serbo-Croatian are closer to one another and much more mutually intelligible than American English versus British English, or North Vietnamese versus South Vietnamese. What ISO/SIL did was to bow to the political pressures brought by hate-filled partisans to declare a rift in the language where none in fact exists. I completely agree with everything Ivan Štambuk says, Serbian, Croatian, and Bosnian are nothing more than extremely close dialects of one language. There is a greater difference along religious lines than across linguistic ones. Serbian spoken by Moslems is closer to the Croatian of Moslems than it is to the Serbian of Catholics, vocabulary-wise. We have had a period of Serbian/Croatian/Bosnian separation that has allowed the parties time to cool off and the smoke to subside, and now they’re beginning to agree that the difference is not a linguistic one. —Stephen 01:25, 25 June 2009 (UTC)
- For those wishing to read details of the differences between Croatian and Serbian, there is a concise summary with specifics on pp.247-250 of Thomas F. Magner's Introduction to the Croatian and Serbian Language (Pennsylvania State University, 1972). The short of it is that the differences he describes don't seem any more extreme than the differences between British and American English, as Stephen has noted. --EncycloPetey 02:10, 25 June 2009 (UTC)
- As a native speaker and because I was asked for my opinion on this, I'd like to say that unification under one header does not do any damage to anyone or anything. When I first started contributing here, 4 years ago, I started with the three headers because I didn't want to offend anyone. Throughout those years I've seen several users delete the other two headings and leave only one, or delete the SH heading and leave only Serbian and Croatian, without Bosnian. Either way there are propagators of ethnic separatedness. I'm completely convinced by Ivan's argument as I have been in the past when we started to work on this issue. Now, to make things clear, Ivan is not Serbian or a Serb and neither am I, so lets stop the issue of Serbian taking over, linguistic genocide, and such things. Clearly, this is a neutral take to simplify things both for our visitors and learners as well as for us, the editors. --Dijan 04:13, 25 June 2009 (UTC)
- If the decision is made to use one header, please state this clearly for any newcomers because this issue will come over and over again. Not everyone will be open-minded and willing to have one umbrella for all teh varieties of Serbo-Croatian. Besides, the separate words Serbian and Croatian are now used by many dictionaries, including Google translate, so users may also be confused. Funnily, I read a preface to an American edition of a Serbian textbook (read Serbo-Croatian), despite trying to be politically correct, they said that basically that the same textbook is basically the textbook for Serbian, Croatian, Bosnian, and Montenegrin with very little variations and 2 alphabets. Anatoli 04:46, 25 June 2009 (UTC)
- Before making any decision, everybody should read w:Serbo-Croatian language, w:Serbian language, w:Croatian language, w:Bosnian language, w:Montenegrin language. These pages provide much more information than Wiktionary discussions could provide. Lmaltier 13:07, 26 June 2009 (UTC)
- If the decision is made to use one header, please state this clearly for any newcomers because this issue will come over and over again. Not everyone will be open-minded and willing to have one umbrella for all teh varieties of Serbo-Croatian. Besides, the separate words Serbian and Croatian are now used by many dictionaries, including Google translate, so users may also be confused. Funnily, I read a preface to an American edition of a Serbian textbook (read Serbo-Croatian), despite trying to be politically correct, they said that basically that the same textbook is basically the textbook for Serbian, Croatian, Bosnian, and Montenegrin with very little variations and 2 alphabets. Anatoli 04:46, 25 June 2009 (UTC)
- If I understand those pages correctly: Standard Serbian, Standard Croatian, Standard Bosnian, and Standard Montenegrin are four different standards with four different literatures, histories, etc., and it wouldn't make sense to try to group them into a single "Standard Serbo-Croatian" (as many have done for nationalist reasons); however, all four standards are part of one language with a continuous range of dialects, and it wouldn't make sense to try to group those dialects into separate "Serbian", "Croatian", "Bosnian", and "Montenegrin" languages (as many have done for nationalist reasons). Is that right? If so, I think there are valid, non–brain-damaged reasons for using the separate language names, but none of them seem to apply here, since we cover all language forms, not just the standards. We might almost as well allow an ==American== language header for Standard American English, which differs from Standard British English at almost every level of language (phonological, lexical, etc.). The major difference is that it's been two hundred years since the British ruled us, and we no longer feel any particular need to push for our language to be treated as separate. (Back in the day, though, there were folks like Noah Webster pushing for a notion of a separate American language; a lot of the U.S./U.K. spelling differences are due to a conscious effort on the part of Americans.) —RuakhTALK 14:02, 26 June 2009 (UTC)
- I also understand that there is no consensus about best terms to be used, whatever the reasons (linguistic, political or both), and that this issue is very sensitive (it's quite obvious from the above discussion). Forbidding Croatian headers while there is an ISO code for Croatian and "The majority of Croatian linguists think that there was never anything like a unified Serbo-Croatian language, but two different standard languages that overlapped sometime in the course of history." (from w:Serbo-Croatian language) might be considered by these linguists as non-neutral (I'm not sure, but it's possible). I feel that this is more a neutrality issue than a linguistic issue, and nothing is more important than neutrality in Wikimedia projects (this is why I suggested to ask the Foundation). Don't you agree?
- The case of English might be be similar from a linguistic point of view, but it's very different from this neutrality point of view: American English has no ISO code and it's not a sensitive issue.
- Allowing headers in at least all language names with an individual ISO code (including Klingon) would be a sound way to be neutral. This is similar to the verifiability/truth issue. Otherwise, this polemic will never end, and other polemics will arise sooner or later (e.g. Bulgarian/Macedonian). Lmaltier 15:11, 26 June 2009 (UTC)
- Lmaltier, 90% of those Croatian linguists who today claim that there never was SC were 20+ years ago writing papers and books that used the term. Almost all of them were taught the course called Serbo-Croatian in schools and collages, and have a degree in "Yugoslav studies" (jugoslavistika). How and why their own (mis)conceptions suddenly changed is of no interest to us.
- We don't care about absolute NPOV - that is a Wikipedia policy that cannot be applied here. We also don't care about OR policy (etymology and some other areas are exceptions) as we've been adding thousands of words you cannot find in any printed dictionary. As I demonstrated above with plenty of the most relevant citations, the term Serbo-Croatian is still abundantly used in English literature, and dumping it purely out of concern for mental state of some petty nationalists is debatable only if you're a psychiatrist. This is English Wiktionary, and >99% of people here, not to mention FL learners of SC, does not find the term "offensive" or "NPOV".
- We already forbade plenty of artificial languages with ISO codes, and plenty of codes are used that are in fact macrolanguages, and their respective individual languages are treated as dialects (e.g. Albanian).
- SIL, i.e. the assignment of ISO or wiki-code, cannot be an absolute arbitrator of what is a "language" and what is not. You're giving too much authority to the institution that I tell you has colossal blunders on its pages. We have our own goals and criteria, formed out of best intention to write "all words in all languages". What SIL, Foundation or some lonesome wiki-cowboy think is completely irrelevant, unless they can backup their opinions with arguments on why exactly is better having 3-4, in most cases identical language sections, instead of one, from the perspective of both the user and the editor. I have not seen a single such argument by anyone in the course of this entire discussion. --Ivan Štambuk 15:37, 26 June 2009 (UTC)
- Lmaltier, I agree that NPOV is important, but your proposal doesn't really encourage NPOV; rather, it encourages entries to be split between a section espousing one POV and three or four sections espousing the other. (See w:Wikipedia:Neutral point of view#POV forks.) It's unfortunate that our rigid structure limits our ability to use NPOV — in a debate over what language applies, we have to choose one, in a debate over what POS applies, we have to choose one, etc. — but your proposal would promote confusion, duplication, and false distinctions, without really providing any NPOV at all. —RuakhTALK 16:02, 26 June 2009 (UTC)
- If I understand those pages correctly: Standard Serbian, Standard Croatian, Standard Bosnian, and Standard Montenegrin are four different standards with four different literatures, histories, etc., and it wouldn't make sense to try to group them into a single "Standard Serbo-Croatian" (as many have done for nationalist reasons); however, all four standards are part of one language with a continuous range of dialects, and it wouldn't make sense to try to group those dialects into separate "Serbian", "Croatian", "Bosnian", and "Montenegrin" languages (as many have done for nationalist reasons). Is that right? If so, I think there are valid, non–brain-damaged reasons for using the separate language names, but none of them seem to apply here, since we cover all language forms, not just the standards. We might almost as well allow an ==American== language header for Standard American English, which differs from Standard British English at almost every level of language (phonological, lexical, etc.). The major difference is that it's been two hundred years since the British ruled us, and we no longer feel any particular need to push for our language to be treated as separate. (Back in the day, though, there were folks like Noah Webster pushing for a notion of a separate American language; a lot of the U.S./U.K. spelling differences are due to a conscious effort on the part of Americans.) —RuakhTALK 14:02, 26 June 2009 (UTC)
- I'm sure that the NPOV policy is as important here as in Wikipedia, because it's also a wiki (but there fewer opportunities to apply it). The "no original research" policy is related to verifiability, and it's very important here too (it's for this reason that CFI requires citations before including a word). I cannot understand how forbidding Croatian headers could meet the NPOV policy. However, if the Foundation is OK with forbidding Croatian headers, and allowing only Serbo-Croatian, I would be OK too. But I would be surprised, and I don't want them to close the project for violation of their NPOV policy. Lmaltier 16:15, 26 June 2009 (UTC)
- to close the project for violation of their NPOV policy - I don't think anyone there has the guts to do that. Anyhow, feel free to ask the Foundation (or whomever is representing it) for comment on possible NPOV violation or whatever, I'll be really happy to read what they have to say.
- Also, NPOV and verifiability have nothing to do with CFI, because here every written instance of language is equally "important". Blogs, USENET, fora...anything goes, as long as it it's stored on some durably archived medium and used by enough people in sufficiently spanning period of time. --Ivan Štambuk 17:56, 26 June 2009 (UTC)
- I'm sure that the NPOV policy is as important here as in Wikipedia, because it's also a wiki (but there fewer opportunities to apply it). The "no original research" policy is related to verifiability, and it's very important here too (it's for this reason that CFI requires citations before including a word). I cannot understand how forbidding Croatian headers could meet the NPOV policy. However, if the Foundation is OK with forbidding Croatian headers, and allowing only Serbo-Croatian, I would be OK too. But I would be surprised, and I don't want them to close the project for violation of their NPOV policy. Lmaltier 16:15, 26 June 2009 (UTC)
I'm sorry to barge in on this little conversation that you have going on here. Especially since I've read only a small part of it. I've been told about this discussion, so I just wanted to state my opinion as a native speaker of the Serbian language. To put it short, this unification is completely ludicrous and baseless. Ivan states that 99% of the words are the same among these languages and I'd like that claim to be substantiated. I don't know the percentage, but if I'd have to guess, it would be around 70%. Let's not reinvent wheel here: there are three recognized languages and, on the other side, we have one that's basically a surpassed political construct. The languages split and are now diverging. Forcefully unifying them is insulting to most of the speakers of those languages as well as to this project. Thank you --Dungodung 21:12, 26 June 2009 (UTC)
- Re: 99% vs. 70%: Those can both be true. For many purposes, the "percentage of words that are the same between Serbian and Croatian" would be something like the percentage of Standard Serbian words that a speaker of Standard Croatian would be equally likely to use, and in the same way (and vice versa). But we're a radically inclusivist dictionary, so for our purposes, it would be the percentage of Serbian words that are ever found in any dialect of Croatian (and vice versa). I don't know anything about this/these language(s), but on the face of it, it seems quite plausible that the former could be 70% while the latter was 99%. —RuakhTALK 22:12, 26 June 2009 (UTC)
- Dungodung is, of course, grossly exaggarating. The overwheling majority of differences among the standards can be accounted to some trivial morpho-phonological alternations that are mutually non-lexically isomorphic (i.e. they don't change the meaning). For example, by the reflex of Common Slavic jat phoneme the Common South Slavic word for "milk" *mlěko yielded SC variant forms mlijéko, mléko and mlíko, which are termed ijekavian, ekavian and ikavian respectively. All the three words are inflected exactly the same way and have the same accentuation. In spoken language, the difference between ijekavian and ekavian is non-lexical (i.e. they are completely mutually intellgible), and such variant pairs/triplet can be treated as one word in 3 spellings/forms. As mentioned above, such difference could (and historically moreover was) be abstracted away by the introduction of generic <ě> symbol, but unfortunatelly it isn't currently so, and someone naïve (or just willing to catch at the straw) might be tempted to treat those as 3 "different words", as opposed to being one and the same word in 3 different forms. A comparison could be drawn for English: suppose English was written in some kind of phonological orthography (like SC is), would bɜ:rd and bɜːd, reflecting rhotic and non-rhotic pronunciation of bird, be two different words or not? Similar to jat, there are also some other variant pairs, like the spelling of word-final -l, verbs ending in -irati (Croatian) that are matched by verbs ending in -isati and -ovati in Bosnian/Serbian (roughly identitical to -ise : -ize distinction in B/A English) and so on. But all in all, as I said, these variant forms are non-lexical, and SC speakers understand them completely naturally, without any difficulties. The amount of really different words in colloquial speech for top 5000 basic words is hardly over 1-2% (my free estimate). --Ivan Štambuk 23:21, 26 June 2009 (UTC)
- Reci mi Dungodung, na kojem je jeziku napisana ova rečenica? Je li ovo:
- hrvatski
- srpski
- bosanski/bošnjački
- srpskohrvatski/hrvatskosrpski
- Kad završiš svoju dubioznu lingvocidnu kontemplaciju, molio bih te da me kao govornika "drugog jezika" prosv(ij)etliš po tom pitanju, kao i da gorespomenutu prevedeš na srpski ako dotična već sasvim slučajno nije na istom (kao nativni govornik "hrvatskog" ne bih znao, no možda ti kao samoprozvani govornik "srpskog" znaš). Ako ti neka r(ij)eč nije jasna, slobodno me pitaj da ti objasnim. Blagodarim na čitanju. --Ivan Štambuk 23:21, 26 June 2009 (UTC)
- Naravno da na tako trivijalnom primeru neće biti (neke velike) razlike. --Dungodung 11:58, 27 June 2009 (UTC)
- Even though common nouns like milk (ml[ij]eko) are lexically same, there are numerous examples of words where Serbian uses one form and Croatian uses another exclusively. Tlak, vlak, kat, kut, ručnik, klokan, rajčica, juha, just to name a few. Those are all common Croatian words, but they are literally non-existent in common Serbian speech, and even though most Serbian-speakers do understand them, newer generations are less likely to be able to understand them, because of political and linguistic divergence that I've already mentioned. I'm not sure if Serbian equivalents of the aforementioned words are at all used in Croatian, but those words sure as hell aren't used in Serbian. That's the point I'm trying to make -- there are still words that differ greatly and that's why it makes sense to treat these languages separately. --Dungodung 11:58, 27 June 2009 (UTC)
- Standard Serbian equivalents of the abovementioned words would be: pritisak, voz, sprat, ugao, peškir, kengur, paradajz, supa. Of listed, pritisak, peškir, paradajz and ugao are more or less very much used throughout the Croatia, the other ones are markedly Serbian. I've never heard rajčica (neologism coined for puristic purposes) being spoken in a vernacular speech (on south they usually use pomidora, in the north paradajz, rajčica is mostly written literary form).
- The crucial point would be your quote: even though most Serbian-speakers do understand them - which categorizes those differences at the same level as lexical pairs of A/B English such as fall / autumn, lift / elevator, trousers / pants etc. It is way above the figure of 70% that you mention. If you, as I explained above, treat pairs such as mlijeko / mleko, sol / so, historija / istorija etc. as variant forms of one and the same word (i.e. disregarding all non-lexical differences in spelling), the percentage of different words for the same sense is closer to some 1-2%. When compiling a dictionary that should contain all the words spoken by all Croats, Bosniaks, Serbs, Montenegrins, Yugoslavs, etc. - it makes much more sense to treat the common core as a single language in one ==Serbo-Croatian== section, and mark the regional differences by means of context labels, usage notes, alternative forms header and similar. This is the method that all top scholarly English literature practices, because it makes absolutely no sense for a foreigner to learn "Croatian", in all its intricate complexities, and not make that extra 5% effort to learn "Serbian", "Bosnian" and "Montengrin" too.
- The divergence you speak about is exaggerated - Serbian and Bosniak TV shows are broadcasted on Croatian TV stations without subtitles (same goes for movies in cinema), Croatian journalists write on Serbian news portals (e.g. e-novine.com, b92.net), Croatian actors participate in Serbian TV show (e.g. I've just read today that Nikolina Pišek signed for some in-production Serbian sit-com), common TV shows are produced with Serb/Croat/Bosniak/Montenegrin participants (e.g. Operacija trijumf, which was quite popular among younger generation), not to mention Internet fora, USENET, chatrooms.. One can easily argue that converence brought by the mass media and Internet-based technologies nullified all the linguocidal damage committed by the neo-fascist regimes of the 1990s. --Ivan Štambuk 12:54, 27 June 2009 (UTC)
- I never stated that the speakers of the languages aren't mutually intelligible. In most cases, they are. But I'm not about to prove my points even more. I came here to make a comment because I was asked to, not because I care, seeing as this is not a wiki I'm involved in (other than from a user perspective). So, whatever the outcome of this discussion may be, I'm fine with it. It's just that I think it's wrong to treat the languages equally, even though they are quite similar. Over and out --Dungodung 23:43, 27 June 2009 (UTC)
- When I was growing up in the socialist Czechoslovakia, Czech and Slovak TV shows were broadcasted on the Czechoslovak TV without subtitles. Slovak and Czech are mutually intelligible, and yet they are treated separately in Wiktionary. --Dan Polansky 08:45, 28 June 2009 (UTC)
- Yes, but standard Czech and Slovak are based on different dialects (albeit close ones), whilst B/C/S are based on the same (Neoštokavian). Unlike Czech and Slovak, standard B/C/S have identical phonology and 99% of grammar (same inflectional endings for nouns, adjectives and verbs, minor differences only in spelling for Future I for -ti verbs - but pronounced the same). Indeed, mutual intelligibility is not a criterion for differing languages in Wiktionary (same goes for Hindi and Urdu, Macedonian and Bulgarian, Romanian and Moldovan, Scandinavian Germanic languages etc.) - but here the problem is that there is not just a pair of languages (but a triplet, possibly even more in a few months) who share the same script, the differences among them are arguably much less then either of other mutually intellegible pairs Wiktionary currently separates, and thus much more is gained by unifiying rather than separating approach in terms of reducing the needless redundancy and enhancing learning experience. --Ivan Štambuk 09:43, 28 June 2009 (UTC)
- I am not saying that the relation between Czech and Slovak is like the relation between Serbian and Croatian. I am only saying that arguing with mutual intelligibility in support of Serbo-Croatian headings is logically invalid, as it equally well supports Czechoslovak headings. --Dan Polansky 08:47, 29 June 2009 (UTC)
- I've mentioned that already even before you made your remark. We have mutually intelligible languages based on the same or distinct dialect treated at different L2 sections, as well as different dialects which are not easily mutually intelligible treated collectively at one L2 section (when treating language as a "collection of dialects", by national self-identification of speakers). Literary Czech and Slovak were intentionally made as differing as possible, whilst literary Serbo-Croatian varieties have had a common unification era for almost 150 years. Has history turned out a bit differently, Czechoslovakian language might still be very alive (or had followed the footsteps of SC in "disintegration"). Modern standard languages are artificial sociological constructs, planned and architected, taught and distributed. But these are all irrelevant details: the most important thing to have in mind are the goals of this project, the issues resolved and the benefits gained by this scheme, and absolutely nothing else. --Ivan Štambuk 09:36, 29 June 2009 (UTC)
- I am not saying that the relation between Czech and Slovak is like the relation between Serbian and Croatian. I am only saying that arguing with mutual intelligibility in support of Serbo-Croatian headings is logically invalid, as it equally well supports Czechoslovak headings. --Dan Polansky 08:47, 29 June 2009 (UTC)
- Yes, but standard Czech and Slovak are based on different dialects (albeit close ones), whilst B/C/S are based on the same (Neoštokavian). Unlike Czech and Slovak, standard B/C/S have identical phonology and 99% of grammar (same inflectional endings for nouns, adjectives and verbs, minor differences only in spelling for Future I for -ti verbs - but pronounced the same). Indeed, mutual intelligibility is not a criterion for differing languages in Wiktionary (same goes for Hindi and Urdu, Macedonian and Bulgarian, Romanian and Moldovan, Scandinavian Germanic languages etc.) - but here the problem is that there is not just a pair of languages (but a triplet, possibly even more in a few months) who share the same script, the differences among them are arguably much less then either of other mutually intellegible pairs Wiktionary currently separates, and thus much more is gained by unifiying rather than separating approach in terms of reducing the needless redundancy and enhancing learning experience. --Ivan Štambuk 09:43, 28 June 2009 (UTC)
- When I was growing up in the socialist Czechoslovakia, Czech and Slovak TV shows were broadcasted on the Czechoslovak TV without subtitles. Slovak and Czech are mutually intelligible, and yet they are treated separately in Wiktionary. --Dan Polansky 08:45, 28 June 2009 (UTC)
- I never stated that the speakers of the languages aren't mutually intelligible. In most cases, they are. But I'm not about to prove my points even more. I came here to make a comment because I was asked to, not because I care, seeing as this is not a wiki I'm involved in (other than from a user perspective). So, whatever the outcome of this discussion may be, I'm fine with it. It's just that I think it's wrong to treat the languages equally, even though they are quite similar. Over and out --Dungodung 23:43, 27 June 2009 (UTC)
- BTW, Moldovan is identical to Romanian, the name Moldovan was/is used for political reasons. There is still an argument going on (and there were polls) whether they should call the language of Moldova Romanian or Moldovan. Although I am Russian, I have to say that the Russian influence has been replaced with the Romanian, although many Moldovans are fluent in Russian, they replace Russian words (often used in Moldova) with Romanian when they speak with Romanians. Languages/dialects diverge more when their speakers want to be different or the other way around when they want to be close. With Moldovan/Romanian, the polls showed a split in opinions about it.Anatoli 11:41, 28 June 2009 (UTC)
- I agree with Ivan Štambuk about closeness of standard Serbian, Croatian and other recently defined varieties - Bosnian and Montenegrin. I never learned or was exposed to much of Serbo-Croatian language(s) but all Slavic languages have a lot of common vocabulary, which was estimated at more than 60%, including the most distant varieties, like Russian and Croatian variety of Serbo-Croatian or Russian and Czech. These two pairs may seem not so mutually comprehensible at first, often because of the pronunciation. Varieties of English, or especially Arabic differ much more than Croatian and Serbian. Even Russian and Serbian have 71% of common roots/words, here's a Swadesh list (in Russian): [8]. Well, then there was no real political need to separate Serbian and Croatian. Or Wictionary's list: Swadesh_lists_for_Slavic_languages, you can always find examples like nappy/diaper, which don't make American and British English mutually unintelligible. Anatoli 12:34, 27 June 2009 (UTC)
- I wrote a small rationale for merging at the proposed WT:ASH policy talk page, that contains the basic arguments, with everything what has been said here in mind. I advise everyone interested to read and comment on it, because once there would be no community feedback for a few days I'll put the proposal to vote. --Ivan Štambuk 13:27, 28 June 2009 (UTC)
- The rationale, small or not, has almost 3400 words, including the quoted text that it contains, which has 1200 words. I hope the discussion is going to continue here in Beer Parlour, the main policy forum which many of the Wiktionary contributors already monitor. --Dan Polansky 09:11, 29 June 2009 (UTC)
- BP is a general policy discussion forum, not a language-specific one. At best, it can serve as a noticeboard for such specific discussions on individual language policy pages. This discussion is more of an exception than a general rule. If you have specific remarks on why exactly the proposed unification scheme wouldn't work, please leave it there. If it's too lengthy for you to read, you're probably not that interested in the policy in the first place. --Ivan Štambuk 09:36, 29 June 2009 (UTC)
- I would still like the discussion to continue in Beer Parlour. There are no language-specific policy forums. I for one do not want to monitor yet another page. Given the obvious sensitivity of the issue, it should IMHO be discussed in the full light of Beer Parlour, so to speak, rather than in an obscure talk page. If that was done when the WT:ASC was first created, we could have possibly spared ourselves the present discussion, as it would have been easier for Robert Ullmann to notice the discussion is ongoing and raise his points earlier. In any case, just to put the same point differently and broadly, important and controversial policy discussions, language-specific or not, should run through a highly visible forum. --Dan Polansky 10:28, 29 June 2009 (UTC)
- There are language specific policy forums - the talk pages of their respective (draft) policy pages. Take a look at the discussions at Wiktionary talk:About Latin, Wiktionary_talk:About_Hebrew or Wiktionary_talk:About_Ancient_Greek for example. It would be silly to discuss all the things discussed there in the BP, when there is only a small group of active contributors really interested.
- Ullmann was noted on this a long time ago. I've personally posted a notice in the BP on March 2nd [9], and requested for interested parties to comment on the proposal talk page. Only one user commented (Carolina wren), and I hopefully answered thoroughly to all of her queries (which becomes a bit difficult if the interlocutor isn't knowledgeable on SC, and forms his opinions on the basis of miscellaneous bits collected here and there - I hope that the illustration of how the unification scheme would work in real texts such as he Universal Declaration his dispelled that kind of prejudice.). I am very saddened by the fact that the discussion was resurrected in such unpleasant overtones here, introducing a great deal of controversy where there is in fact minimal one.
- I agree that any kind of potentially controversial discussion should be held at highly-visible forum, but only those that couldn't have been held at some more specific forum such as language (draft) policy talk page. BP should be then used as a noticeboard for such discussions. --Ivan Štambuk 10:53, 29 June 2009 (UTC)
- Clearly, there is the potential for more than a technical-level issue here. I would think that you could see there is little support for anything that could be seen as subtracting from existing content in the unmerged languages. We haven't heard much opposition to the use of Serbo-Croatian. No one would expect anyone to spend time entering, maintaining, and enhancing language sections that they did not choose to. If a language dies out because the population that might have spoken it no longer chooses to, that is not linguistic genocide. If some of the languages under discussion here are not maintained, that is a wholly analogous phenomenon.
- If you need a Vote to show that the community thinks Serbo-Croatian merits full technical support and inclusion, I don't doubt that you could get it. But I doubt that anyone favors simply altering L2 headers en masse, with or without a bot. My suggestion, just before the first arbitrary edit break, about the conditions under which folks might be more likely to accept changing L2 headers seems to me to be about as far as one could push the elimination of the language headers you now disfavor. No one seemed to object to that characterization of what might be acceptable, though perhaps that is because it wasn't read. DCDuring TALK 14:00, 29 June 2009 (UTC)
- But I doubt that anyone favors simply altering L2 headers en masse, with or without a bot. - I and other SC contributors have been doing exactly that for months, manually deleting redundant sections, cleaning up and expanding in the process, with the proposed policy in mind (e.g. mutually linking between variant forms). I see no problems with this approach. It cannot be done by a bot, it must be done by a human.
- L2 ==Bosnian==, ==Croatian==, and ==Serbian== cannot stay together with ==Serbo-Croatian==. By leaving them it makes no sense to create "unified section" in the first place. Labels for those imaginary languages fabricated in the 1990s must go away. --Ivan Štambuk 14:22, 29 June 2009 (UTC)
- I would still like the discussion to continue in Beer Parlour. There are no language-specific policy forums. I for one do not want to monitor yet another page. Given the obvious sensitivity of the issue, it should IMHO be discussed in the full light of Beer Parlour, so to speak, rather than in an obscure talk page. If that was done when the WT:ASC was first created, we could have possibly spared ourselves the present discussion, as it would have been easier for Robert Ullmann to notice the discussion is ongoing and raise his points earlier. In any case, just to put the same point differently and broadly, important and controversial policy discussions, language-specific or not, should run through a highly visible forum. --Dan Polansky 10:28, 29 June 2009 (UTC)
- BP is a general policy discussion forum, not a language-specific one. At best, it can serve as a noticeboard for such specific discussions on individual language policy pages. This discussion is more of an exception than a general rule. If you have specific remarks on why exactly the proposed unification scheme wouldn't work, please leave it there. If it's too lengthy for you to read, you're probably not that interested in the policy in the first place. --Ivan Štambuk 09:36, 29 June 2009 (UTC)
- The rationale, small or not, has almost 3400 words, including the quoted text that it contains, which has 1200 words. I hope the discussion is going to continue here in Beer Parlour, the main policy forum which many of the Wiktionary contributors already monitor. --Dan Polansky 09:11, 29 June 2009 (UTC)
- I've created a vote: Wiktionary:Votes/pl-2009-06/Unified Serbo-Croatian --Ivan Štambuk 07:43, 30 June 2009 (UTC)
An international embassy has been built for any trans- or inter-wiktionary exchange. JackPotte 06:45, 31 May 2009 (UTC)
- But you have written Welcome to the French Wiktionary... Furthermore, I consider Russian indispensible, since Russian is the language spoken by the greatest number of people on the Europæan continent. I shall propose my translation on the talk page and urge a native speaker to verify it. The uſer hight Bogorm converſation 14:38, 31 May 2009 (UTC)
- Umm, what is this for? Conrad.Irwin 18:16, 31 May 2009 (UTC)
- For people with scarce command of English, but who are able to converse in other international languages, e. g. French, Chinese, Esperanto and so forth. The uſer hight Bogorm converſation 18:38, 31 May 2009 (UTC)
- Which raises the following quæstion: many Wiktionaries have in their welcoming templates a line like You do not speak language X? Go to our embassy., mainly in English. But Template:Welcome does not have this line. I suggest inserting four lines in small script in German, French, Russian and Chinese with the same content. What do you think? We can not expect from every novice here to speak English flawlessly, especially if he uses Wiktionary for expanding his vocabulary. The uſer hight Bogorm converſation 18:42, 31 May 2009 (UTC)
- If said user plans to use Wiktionary he will need at least a basic fluency in English, everything is labelled in English, defined in English and translated to English (you can't even change the interface to be not in English unless you already know how to use MediaWiki). Given the very low proportion of people who will try to use Wiktionary without speaking a bit of English, I don't think there is a need for a seperate forum - though perhaps we should allow multilingual discussion on WT:ID. Conrad.Irwin 19:07, 31 May 2009 (UTC)
- Conrad, English is still the fourth most spoken language after Chinese, Spanish and Hindi (here, the second column) and if Chinese, Spanish and Hindi Wiktionaries allow embassies for foreigners with insignificant knowledge of their language, it would be impolite if they are deprived of the due reciprocity here. The uſer hight Bogorm converſation 19:29, 31 May 2009 (UTC)
- People who post on WT:ID are almost guaranteed a reply, as a large number of people watch that page, or at least visit it from time to time. Posts to the Embassy are unlikely to get a reply except for from the people who have read this thread. It's not that I don't want to talk to them, it's just that I don't think segregation is a good solution. Conrad.Irwin 21:38, 31 May 2009 (UTC)
- Conrad, English is still the fourth most spoken language after Chinese, Spanish and Hindi (here, the second column) and if Chinese, Spanish and Hindi Wiktionaries allow embassies for foreigners with insignificant knowledge of their language, it would be impolite if they are deprived of the due reciprocity here. The uſer hight Bogorm converſation 19:29, 31 May 2009 (UTC)
- If said user plans to use Wiktionary he will need at least a basic fluency in English, everything is labelled in English, defined in English and translated to English (you can't even change the interface to be not in English unless you already know how to use MediaWiki). Given the very low proportion of people who will try to use Wiktionary without speaking a bit of English, I don't think there is a need for a seperate forum - though perhaps we should allow multilingual discussion on WT:ID. Conrad.Irwin 19:07, 31 May 2009 (UTC)
- That's a good point. Since (some) other Wiktionaries have embassies, we should probably keep Wiktionary:Embassy as a target for interwiki links, but I'd be quite happy with it just having a brief paragraph in each language inviting visitors to comment in their own language at BP or ID. —RuakhTALK 22:48, 31 May 2009 (UTC)
- That would make sense, and also a brief description of how to useWT:BABEL would not go amiss. Conrad.Irwin 23:09, 31 May 2009 (UTC)
- Sounds good (Ruakh's, Conrad's ideas).—msh210℠ 16:41, 1 June 2009 (UTC)
- That would make sense, and also a brief description of how to useWT:BABEL would not go amiss. Conrad.Irwin 23:09, 31 May 2009 (UTC)
- That's a good point. Since (some) other Wiktionaries have embassies, we should probably keep Wiktionary:Embassy as a target for interwiki links, but I'd be quite happy with it just having a brief paragraph in each language inviting visitors to comment in their own language at BP or ID. —RuakhTALK 22:48, 31 May 2009 (UTC)
- We can't go by reciprocity, because that would obligate us to include notices in 100 languages, sooner or later. Perhaps we should provide notes in the languages of the Wiktionaries with most editors, since this is a place to communicate with ambassadors: foreign-language Wiktionary editors—not necessarily, and not only foreign-language writers. —Michael Z. 2009-05-31 22:16 z
- Huh? I don't understand what this Embassy is supposed to be good for. I don't see any analogy between the page created and real-world embassies. He who speaks no English should not edit English Wiktionary.
- Admittedly, pages have been created in other Wiktionaries that carry in their title a foreign-language translation of "embassy". But from having looked there, I failed to notice any worthy use of these pages. I mean the following pages:
- I see no point in replicating in English Wiktionary that which does not work in the original site. --Dan Polansky 15:32, 1 June 2009 (UTC)
- It doesn't necessarily have to be people with English as a second language; it can just be a way of coordinating erm... multilingual coordination. Perhaps rewriting it is better than deleting it, or making a redirection out of it. Mglovesfun 15:41, 1 June 2009 (UTC)
- Having said that, this page could do that as well, couldn't it? Mglovesfun 15:42, 1 June 2009 (UTC)
- If Beer parlour would not suffice for the topics under the head "international coordination", a page called "Wiktionary:International coordination" could be created. However, I don't see what the subject matter of international coordination is supposed to be. One topic belonging to the subject is the logo, which has been handled in Beer parlour. Another one is the proposal for unification of category structures across all the Wiktionaries, which I hope will be refused, and could as well be posted to Beer parlour. I am short of further ideas.
- I have noticed meta:Wikimedia Embassy, which links to Wikipedia "embassies". From having looked at several ones in the languages that I understand, Wikipedia embassies mainly list, per language, people who understand the language and are willing to respond to inquiries. An example: W:Wikipedia:Local Embassy. Also German Wiktionary's de:Wiktionary:Botschaft mainly lists contacts per language. I doubt that this is very useful, though. Wikipedia embassies host no discussions. --Dan Polansky 16:34, 1 June 2009 (UTC)
- For me the 2 interests of the Wiktionary:Embassy system are :
- To compare and synchronize all wikies (eg: did you know that the fr.wikt proposes a specific filters search engine (eg: phonetic, rhymes and anagrams) since the last week ? We can also propose into it to export the translations "assisted editing" for that any ambassador would bring it into his known wiki).
- All wikies Beer parlours are too long to follow if we are searching something (or everything) to import into another wiki.
- JackPotte 21:17, 1 June 2009 (UTC)
- A multilingual-coordination page should exist on meta (it probably does already, but no-one uses it) so that every Wiktionary can talk in the same place instead of having every conversation in 200 disparate embassies (which no-one will use, for exactly the same reason). Discussions that affect a local wiki should take place on that wiki's discussion forum, it is not up to a "central committee" to dictate what each Wiktionary does. Conrad.Irwin 23:36, 1 June 2009 (UTC)
- To my mind http://meta.wikimedia.org/wiki/Wikimedia_Forum name isn't enough explicit for these functions. JackPotte 07:32, 3 June 2009 (UTC)
- We (at sv:wikt) have seen that people have used other wiktionaries (chiefly en:wikt) as a source for translations. Obviously we are not alone, as Irish speakers since moved around sending messages to - as I understand - a large number of wiktionaries that the correspondingly created entries of names of countries failed to show some important information concerning use of definite article and, if memory serves, lenition(?). This would have been facilitated by a single "alert" page for all wiktionaries.
- Though that may or may not be what Jack refers to... \Mike 23:02, 5 June 2009 (UTC)
- A multilingual-coordination page should exist on meta (it probably does already, but no-one uses it) so that every Wiktionary can talk in the same place instead of having every conversation in 200 disparate embassies (which no-one will use, for exactly the same reason). Discussions that affect a local wiki should take place on that wiki's discussion forum, it is not up to a "central committee" to dictate what each Wiktionary does. Conrad.Irwin 23:36, 1 June 2009 (UTC)
- For me the 2 interests of the Wiktionary:Embassy system are :
- It doesn't necessarily have to be people with English as a second language; it can just be a way of coordinating erm... multilingual coordination. Perhaps rewriting it is better than deleting it, or making a redirection out of it. Mglovesfun 15:41, 1 June 2009 (UTC)